

はじめに
今回は自然言語処理について基本から解説をしていきます。環境構築がまだの方は以下の記事を参照して、環境構築をすませちゃってください。
▶ 自然言語処理のための環境構築(Windows)については以下の記事をご覧ください

まずはテキストデータの読み込みから始めて、読み込んだテキストデータの正規化や形態素解析をおこなっていきます。形態素解析は「文章を最小の単位に分ける」わかち書き、それらを品詞に分ける工程などがありますが、これらはMeCabライブラリを用いれば一発で処理することができます。形態素解析の後は単語の使用状況の可視化までを扱います。
テキストファイルの読み込み
まずテキストファイルを用意しましょう。江戸川 乱歩の「サーカスの怪人」のデータを使うことにします。このデータは以下で公開されていました。

ダウンロードしたzipファイルを解凍すると「sakasuno_kaijin.txt」が得られます。まずはこのファイルを読み込んでみましょう。ファイルサイズがわからないので1行ずつ読み込むことにしましょう。
text = []
text = []
with open('sakasuno_kaijin.txt',mode='r',encoding='cp932') as f:
for line in f:
text.append(line.rstrip())
content = ''.join(text)
content
ちゃんと読み込めてますね。7行目のrstrip()メソッドは、文字列の右側の文字を除去します。引数charsを指定すると、除去する文字を指定することができます。引数を省略した場合はスペースを削除します。
9行目ではjoin()メソッドでデータの結合をおこなっています。join()メソッドの書式は以下のようになります。
リストに格納された個々の文字列が、「結合時の区切りとなる文字列」で指定した文字で結合されます。今回は何も指定しなかったので直接結合されます。
次に文字の正規化をおこないましょう。数値は半角、カナは全角で統一する処理です。unicodedataというライブラリを用います。正規化の形式としてここでは「NFKC 」を指定しましょう。
# ライブラリのインポート
import unicodedata
content = unicodedata.normalize('NFKC', content)
content
次にこのテキストデータから「本文」のみを取り出しましょう。本文の始まりは「[#「骸骨紳士」は中見出し]」より後の部分。本文の終わりは「底本:「魔法人形/サーカスの怪人」」の手前までですね。この部分を取り出してみましょう。正規表現を使うと簡単ですね。
import re
pattern = re.compile(r'^.+(\[#「骸骨紳士」は中見出し\].+底本:「魔法人形/サーカスの怪人」).+$')
body = pattern.match(content).group(1)
print(body)3行目でreモジュールのcompile()を使っています。compile()は、特定の正規表現パターンをオブジェクトとして生成します。次の書式となります。
生成したオブジェクトはmatch()メソッドを使うことができます。contentに対して作成した正規表現パターンでデータを抽出しています。


指定した文字列に挟まれたデータが抽出できていますね。「[#「骸骨紳士」は中見出し]」と「底本:「魔法人形/サーカスの怪人」」の部分は本文ではないので、この部分を削除してしまいましょう。
body = body.replace('[#「骸骨紳士」は中見出し]','')
body = body.replace('底本:「魔法人形/サーカスの怪人」','')形態素解析
ここから形態素解析をしていきましょう。形態素解析は、自然言語で書かれた文を言語上で意味を持つ最小単位(=形態素)に分け、それぞれの品詞や変化などを判別することです。MeCabライブラリを用いると簡単にできます。やってみましょう。
import MeCab
tagger = MeCab.Tagger()
parsed = tagger.parse(body).split('\n')
# 先頭4行の確認
parsed[:4]
末尾も確認しておきましょう。
# 末尾4行の確認
parsed[-4:]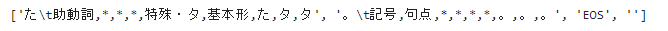
末尾の2つのデータは不要ですね。これを削除してしまいましょう。
# 末尾2要素の削除
parsed = parsed[:-2]
parsed[-4:]
このデータをデータフレームに格納しましょう。まず、データの区切りを考えると「\t」と「,」で区切られていることがわかります。区切り文字を「,」に統一することにしましょう。
# 区切り文字を「,」に統一する
*values, = map(lambda s: re.split(r'\t|,',s),parsed)
values[:-4]
「*values」のように代入文の左辺に * からはじまる変数を置くと,右辺のイテラブルの「残りの要素全部」がリストとして代入されます。
たとえば、次のようにするとイメージが湧きやすいかもしれないですね。
*test, last= map(lambda s: re.split(r'\t|,',s),parsed)
last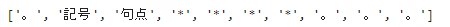
先ほどのvaluesの一番最後の要素がlastに代入されていることわかりますね。このように*がついた変数に残り全部が代入される仕組みになっています。
ではデータフレームに格納することにしましょう。
# カラムの定義
columns = ['表層形','品詞','品詞細分類1','品詞細分類2','品詞細分類3','活用型','活用形','原形','読み','発音']
# データフレームに格納
mecab_df = pd.DataFrame(data=values,columns=columns)
mecab_df.head(4)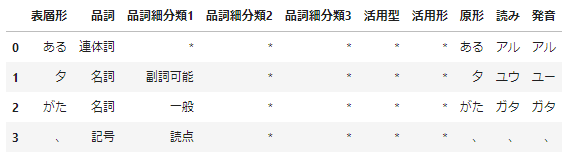
単語の使用状況の可視化
名詞だけを取り出してみましょう。データフレームに「品詞」のカラムがあるのでここで絞り込めばよいですね。
noun = mecab_df.query('品詞=="名詞"')
noun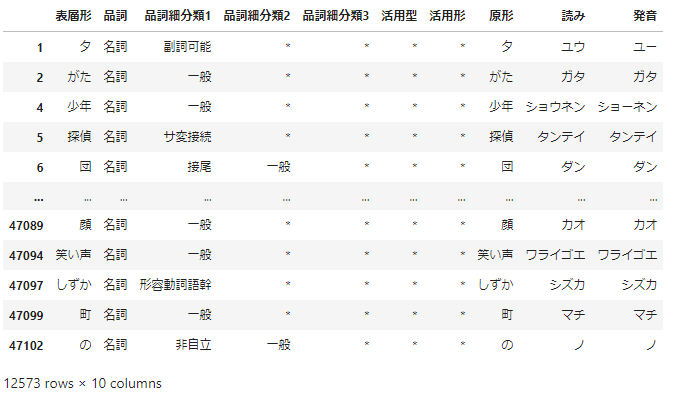
名詞と動詞を抽出したものを作っておきましょう。
# 名詞+動詞を抽出
noun_verb=mecab_df.query('(品詞=="名詞")|(品詞=="動詞")')不要な単語を除外
ここでは不要な単語の除外をしておきましょう。ここでは、’する’, ‘いる’, ‘なる’, ‘れる’, ‘よう’ を除外することにしましょう。
stop_words = ['する', 'いる', 'なる', 'れる', 'よう','傍点']
noun_verb = noun_verb.loc[~noun_verb['原形'].isin(stop_words)]分析を進めていく中で、不要な単語が増えてきたらstop_wordsに加えていけばよいですね。「傍点」については、次のような本文の表記を説明するときに出てくるもので、作品の表現とは関係ないため除外としました。
「ワアッ……。」というとき[#「とき」に傍点]の声があがりました。
単語の使用状況を可視化
さて、単語の使用状況を可視化してみましょう。ここでは名詞についてそれぞれの単語がいくつ出現するかを数えることにしましょう。
count = noun.groupby('原形').size().sort_values(ascending=False)
count.name = 'count'
count = count.reset_index().head(10)
count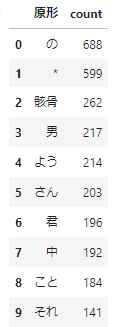
これを可視化しておきましょう。ここまでくれば簡単ですね。
plt.figure(figsize=(10,5))
sns.barplot(x=count['count'], y=count['原形'])
plt.grid()
plt.title('名詞の出現回数TOP10')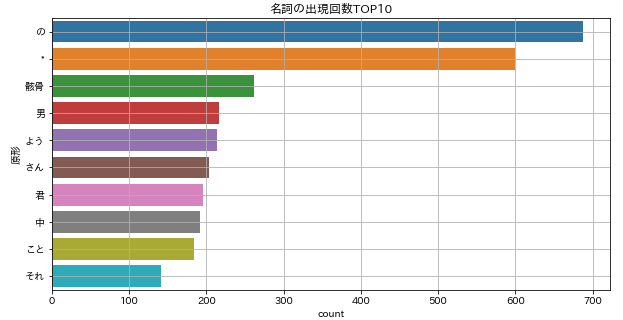
WordCloud
最後にWordCloudを描いてみましょう。
日本語フォントのインストール
日本語フォントがインストールさていない方は、まずはインストールからです。以下のサイトからIPAexフォントをダウンロードしましょう。

フォントのインストール方法は以下のページを見るとわかりやすいかと思います。
WordCloud
日本語フォントの準備ができたらいよいよWordCloudの描画です。ここでは、本文から「名詞+動詞」を抽出したnoun_verbを描画してみましょう。
wordcloudライブラリを使います。
# ライブラリのインポート
from wordcloud import WordCloud
# フォントのパス
font_path = 'C:\\Users\\(ご自分の環境)\\AppData\\Local\\Microsoft\\Windows\\Fonts\\ipaexg.ttf'
# ワードクラウドの描画
cloud = WordCloud(background_color='white', font_path=font_path).generate(''.join(noun_verb['表層形'].values))
plt.figure(figsize=(10,5))
plt.imshow(cloud)
plt.axis('off')
plt.savefig('sample_cloud.png')1~6行目:まずライブラリからWordCloudクラスをインポートし、先ほどインストールした日本語フォントのパスを定義しておきます。
8行目からがWordCloudの描画です。WordCloud()の引数で背景色の指定(background_color)とフォントのパス(font_path)を渡します。generate()は単語を渡すメソッドです。単語は半角スペース区切りで連結して渡しています。imshow()は画像表示用のメソッドで、表示対象として、画像ファイルや画像情報を格納した配列を指定します。

うまくいきました。「サーカスの怪人」という、この作品を読んだことはないですが、WordCloudをみるだけでも、「どくろ」や「悪人」が強調されていて不気味な雰囲気が漂ってますね。
まとめ
今回はテキストデータの読み込みから始めて、形態素解析をして単語の使用状況の可視化、WordCloudとみてきました。WordCloudは使用頻度の高い単語を抽出して強調して表現してくれるので、中身をすべて読まなくても特徴をとらえやすくなりますね。
少し環境準備が大変でしたが、コードはそんなに難しくはなかったですね。
コメント