
はじめに
数値や文字列のようにいろんな種類のデータがあります。このデータの種類のことを型(Type)といいます。数値なら数値型、文字列なら文字列型のように呼び、これらを総称してデータ型と呼びます。
まずはじめに、Pythonの主なデータ型をまとめておきましょう。
- str:文字列型
- int:整数型
- float:浮動小数点型
- bool:ブール型
- datetime:日付型
- list:配列型
- tuple:タプル型
- dictionary:辞書型
はじめはイメージしづらいかもしれませんが、listやtuple、dictionaryのようにデータを格納しておく箱も、数値などと同じデータ型の仲間となります。
今回の「データ型の変換」では、str、int、float、datetimeについて扱うことにします。
データ型の確認
前回、データをざっと確認する方法について学びました。

データは正しく型が認識されていないと、期待したような集計がされず分析もうまくいきません。データを扱ううえでは、「データ型」を意識するようにしましょう。データ型は次のようにすると簡単に調べることができます。
type(オブジェクト)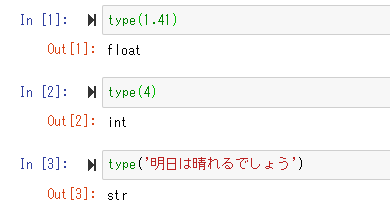
データを読み込んだ時に、自動的に型を認識してくれますが、本来扱ってほしい型となっていない場合もあります。そのような場合には、データ型を変換する必要があります。
データ型の変換
Pythonでの型の変換は組み込み関数が用意されているため非常に簡単です。パターンごとに見ていきましょう。
数値型(intやfloat)から文字列str型へ変換
数値から文字列型への変換には、str()を利用します。引数の数値には、整数int型や浮動小数点float型を指定することができます。 例を見せるまでもないと思いますので、サンプルコードは省略します。
文字列を数値型(intやfloat)へ変換
今度は逆の処理です。文字列を数値に変換することを考えます。この処理にも組み込み関数が用意されており、整数型への変換はint()、浮動小数点型への変換はfloat()を使います。それぞれ、int()の際に指定する引数は、「int型になることができる文字列」、float()の際に指定する引数は、「float型になることができる文字列」を指定しなければならないことに注意してください。
日付datetime型から文字列str型への変換
datatime(日付)型から文字列への変換には、strftimeを利用します。
datetimeオブジェクト.strftime (フォーマット)フォーマットの部分は、次のように指定します。
年:%Y、月:%m、日:$d、時:%H、分:%M、秒:%S
こちらはサンプルを記載しておきます。
# datetimeライブラリのインポート
import datetime as dt
# 日付型の変数を作成
sample=dt.datetime(2020,1,13,12,59,6)
# 型の確認
type(sample)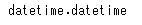
このsampleという変数の型を文字列型に変換することにします。
sample1=sample.strftime("%Y/%m/%d %H:%M:%S")
print(type(sample1))
print(sample1)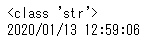
このようにstr型に変換され、表記も「2020/01/13 12:59:06」のように変更することができました。ちなみにstrfの「f」は「format」と覚えておくとわかりやすいと思います。
文字列str型から日付datetime型への変換
文字列からdatatime(日付)型への変換には、strptimeを利用します。
※datetimeをdtでインポートしている場合の例としています。
dt.datetime.strptime (文字列, フォーマット)strptimeでは、最初の引数で指定された日付形式の文字列をdatetime型に変換します。もう1つの引数は、日付形式の文字列のフォーマットを指定します。こちらもサンプルを記載しておきます。
sample2=dt.datetime.strptime(sample1,"%Y/%m/%d %H:%M:%S")
print(type(sample2))
print(sample2)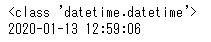
このように文字列型をに日付型に変換することができました。ちなみにstrpの「p」は「parse」と覚えておくとわかりやすいと思います。
ちなみに、日付型に変更するだけであれば、pandasのto_datetimeを使うてもあります。これは次のようにやります。
sample3=pd.to_datetime(sample1)
print(type(sample3))
print(sample3)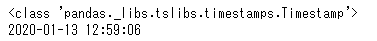
データフレームの列ごと型変換する
ここではあらたにサンプルデータを用意して説明することにします。
df=pd.DataFrame({'columns1':[1,2,3,4,5],
'columns2':['a','b','c','d','e'],
'columns3':[True,True,False,True,False]})
df
各列の型は次のようになっています。
df.info()
型はdtypeを使って次のようにしても調べることができます。
print(df['columns1'].dtype)
print(df['columns2'].dtype)
print(df['columns3'].dtype)
さらにdtypesを使うと、まとめて型を調べることができます。
df.dtypes
この列の型を変換するには、astype()を使います。column1は整数型ですが、これを浮動小数点型に変えてみましょう。
df['columns1'].astype('float')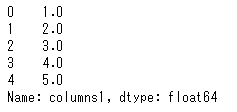
このようにastypeの中で型を指定するだけです。実は、astype()は辞書型で指定することもできます。
df.astype({'columns1':'float',
'columns2':'category',
'columns3':'str'}).dtypes
まとめ
いかがでしたでしょうか?今回は、型変換を扱いました。型変換したあとには、ちょっとした処理が必要になることもあります。
▶ 日付の処理には一定のパターンがあります。日付型の処理に特化した解説記事もあります。

▶ 基準の日時からの経過時間を扱いたい場合は、timedelta型を使います。こちらの解説記事をどうぞ

桁数を揃えてゼロ埋めしたり、小数点の有効数字などを考慮する方法などは、次のブログ記事に詳しく掲載されていましたので、ご紹介しておきます。
コメント