
はじめに
今回はPythonで曜日を取り扱う方法を紹介します。データを集計しているときに、曜日ごとに集計して比較したくなることがありますよね。Webページのアクセス状況なども、妖美ごとに特徴があることが多いですよね。日付から簡単に曜日を算出する方法を整理しましょう。
サンプルデータ
まず、サンプルデータを作りましょう。ある動物園の日毎の来場者数のデータ、という想定でデータを作りましょう。
# ライブラリのインポート
import pandas as pd
import datetime as dt
import numpy as np
# 2020/8/11~2020/9/30までの連続した日付のデータ
date_list=pd.date_range('2020-08-11','2020-09-30')
# 来場者数のデータ
visitors_list=np.random.randint(40,200,51)
# データフレームの作成
df_date=pd.DataFrame({'日付':date_list,'来場者数':visitors_list})
df_date.head()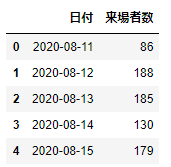
曜日の取り扱い
このデータを曜日ごとに集計してみましょう。まずは、各日付が何曜日であるかを知る必要があります。実は、曜日はdatetimeライブラリのweekday()メソッドで簡単に求めることができます。datetimeオブジェクトに対してweekday()メソッド()を使用すると、数字が返ってきます。これは、0が月曜日、1が火曜日・・・6が日曜日に対応しています。
# 曜日の算出
df_date['曜日']=df_date['日付'].apply(lambda x:x.weekday())
df_date=df_date[['日付','曜日','来場者数']]
df_date.head()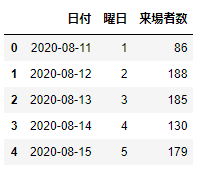
このように簡単に曜日を算出できます。でも、数字のままではわかりにくいですね。これをrepalceで変換しておきましょう。
# 曜日の表示を変換
df_date['曜日']=df_date['曜日'].replace({0:'月曜日',1:'火曜日',2:'水曜日',3:'木曜日',4:'金曜日',5:'土曜日',6:'日曜日'})
df_date.head()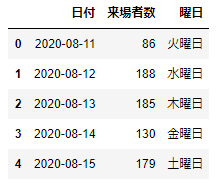
これで見やすくなりましたね。架空のデータですが、曜日別の集計をしてみましょう。
df_date.groupby('曜日').agg({'来場者数':'mean'}).reset_index().sort_values(by='来場者数',ascending=False)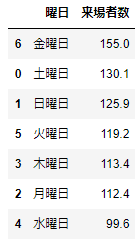
曜日別の平均来場者数は、金曜日が最多、次に、土曜日、日曜日と続きます。週末の来場者が多い、という結果となりました。
まとめ
いかがでしたか?曜日別に集計することで特徴を見つけられることがあります。こんなに簡単に曜日を算出できるのは、ありがたいですね。
コメント