
- データを分析をしたいが、どこから始めてよいかわからない方
- データを仕事に活かしたいが、データの解釈の仕方がわからない方
- 統計学を体系的に学んだことがない、初学者の方
▶ 統計学の諸学者向けの記事を書いています。こちらの記事も参考にしてください。

はじめに
統計学を学んだことがない方を対象に基本から解説しています。今回は、前回扱った「代表値」をPythonで求める手順を基本から解説していきます。平均値、中央値、最頻値の順に扱っていきます。記事を最後まで読むことで、これらの代表を簡単にPythonで算出できるようになります。
代表値の算出
サンプルデータを用意しておきましょう。まずは今回使うライブラリをインポートしておきましょう。
# ライブラリのインポート
import pandas as pd
import numpy as np
from scipy import stats
import random
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
%matplotlib inline
# サンプルデータの作成
money=[300,500,1000,1500,2000]
moneys=random.choices(money,k=12)
spend=[75,90,120,130,170,199,283]
spends=random.choices(spend,k=12)
animals=pd.DataFrame({'どうぶつのなまえ':['らくだ','ねこ','いぬ','きりん','ぞう','ぶた','あらいぐま','さる','ぺんぎん','くじら','いるか','しまうま'],
'せいべつ':['男','女','女','女','男','女','男','女','女','女','男','男'],
'とし':[8,3,6,9,10,21,2,3,7,2,21,34],
'おこづかい':moneys,
'つかったおかね':spends})animalsというデータフレームを作成しました。中身を確認しておきましょう。
animals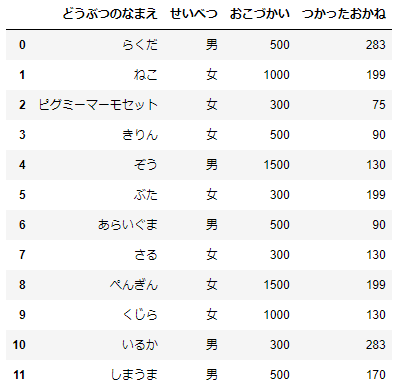
どうぶつたちの「とし」「せいべつ」「おこづかい」「つかったおかね」のデータですね。「とし」と「せいべつ」について分布をみておきましょう。
# どうぶつたちの年齢の分布
sns.displot(animals['とし'],kde=False)
plt.title('どうぶつたちの年齢')
plt.grid()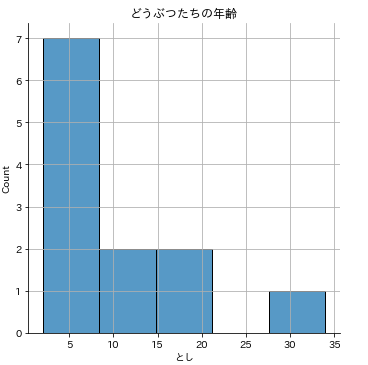
# どうぶつたちの性別の分布
sns.catplot(x='せいべつ',data=animals,kind='count')
plt.title('どうぶつたちのせいべつ')
plt.grid()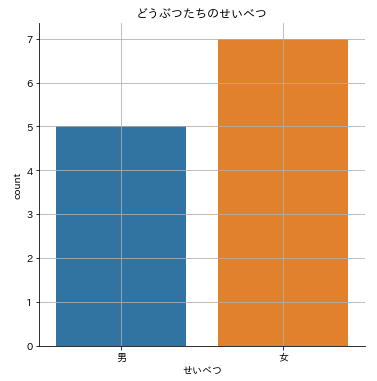
このデータを使って、代表値を算出していきましょう。
平均値
平均値はmean()で求めることができます。np.mean()の中にarrayを入れる、あるいは、Seriesに対してmean()メソッドを使うことでも計算できます。また、カテゴリ変数でgroupbyしたあとにmean()を指定するパターンもよく使うので覚えておくとよいでしょう。
- np.mean()
- df[‘column’].mean()
- df.groupby(‘column’).mean()
実際にやってみましょう。まずはnp.mean()で計算してみます。
# np.mean()で算出
np.mean(animals['とし'])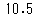
同様にdf[‘column’].mean()でもやってみましょう。
# df['columns'].mean()で算出
animals['とし'].mean()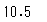
どちらの算出方法でも(あたりまえですが)全く同じ値になります。最後にカテゴリ変数ごとに平均値を算出する例もみておきましょう。このデータフレームは「せいべつ」というカテゴリ変数をもっていましたね。男女で「とし」や「おこづかい」「つかったおかね」の平均がどのくらい違うかを見てみましょう。
# せいべつごとの各カラムの平均
animals.groupby('せいべつ').mean()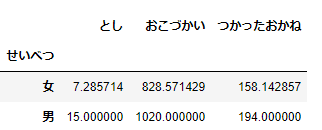
簡単ですね。1行のコードで簡単に「せいべつ」ごとの各列の平均値を求めることができました。
中央値
次に中央値を見ていきましょう。前回の繰り返しになりますが、中央値は全体の変化を見たり比較するときには向かないという特徴がありました。ただ、外れ値には強い代表地でしたね。この中央値は平均値の場合と同様に、np.median()で求めることもできますし、df[‘columns’].mean()で求めることもできます。また、カテゴリ変数でgroupbyして使うこともできます。
- np.median()
- df[‘column’].median()
- df.groupby(‘column’).median()
実際にやってみましょう。まずはnp.median()からです。
# np.median()で算出
np.median(animals['とし'])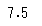
df[‘columns’].median()でも求めておきましょう。
# df['columns'].median()で算出
animals['とし'].median()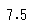
ちゃんと同じ値が返りますね。平均値の場合と同様にgroupbyも見ておきましょう。
# せいべつごとの各カラムの中央値
animals.groupby('せいべつ').median()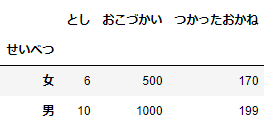
最頻値
最後に最頻値をみておきましょう。最頻値を求める場合には、scipyモジュールのstatsを利用します。これを利用したstats.mode()で求める方法と、Seriesに対してmode()メソッドを使う方法があります。
- stas.mode()
- df[‘column’].mode()
実際にやってみましょう。まずは、stats.mode()からです。
# stats.mode()で算出
stats.mode(animals['とし'])この返り値は2つあり、「最頻値」と「個数」が返ってきます。
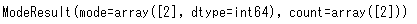
「mode」というのが最頻値で「2」ですね。その個数がcountで「2」となります。このような場合、次のように変数に入れておくとよいですね。
mode,count=stats.mode(animals['とし'])
print(mode)
print(count)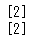
df[‘column’].mode()での算出も見ておきましょう。
# df['column'].mode()で算出
animals['とし'].mode()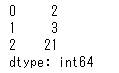
こちらは最頻値をSeriesで返してくれます。「2」「3」「21」とありますね。どういうことでしょうか?実際に数を数えてみましょう。
# 「とし」のvalueごとに個数を数える
animals['とし'].value_counts()
「2」「3」「21」が2個ずつあり、同率で最頻値だった、というわけです。このように求め方によって挙動の差があるので注意しましょう。
まとめ
いかがでしたか?今回は代表値をPythonで算出する方法を扱いました。他にもパターンがありますが、まずはこれをおさえておけば十分です。
コメント