
はじめに
今回はrank()メソッドを扱います。一言でいうと、順位付けをするものとなります。データ分析の過程で、順位をつけることありますよね。そんなときに活躍するのがrank()メソッドです。同一値の処理のオプションなども確認しておきましょう。
条件を指定してデータフレームから必要なデータを抽出したい場合は、以下の記事を参考にしてください。

サンプルデータの作成
まずサンプルデータを作っておきましょう。ここでは動物たちの得点をまとめたデータが提供されているとします。
# ライブラリのインポート
import pandas as pd
# サンプルデータの作成
df_sample=pd.DataFrame({
'名前':['らくだ','きりん','ぞう','パンダ','うさぎ','らいおん','ねこ'],
'得点':[100,92,92,89,73,88,93]
})
df_sample
このデータの得点をもとにランクを付与して並べ替えてみましょう。
rank()メソッドを使ってみる
rank()メソッドを呼ぶと、デフォルトでは各列が昇順で順位付けされます。同一値は平均順位となり、文字列はアルファベット順に比較されます。日本語とアルファベットが混在しているようなケースでは、「アルファベット、ひらがな、カタカナ、漢字」という順になります。
さっそく見ていきましょう。
df_sample.rank()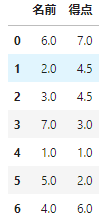
各列の順位付けができました。でも、ちょっと見づらいですね。元の列も残すように表示してみましょう。
_df=pd.concat([df_sample,df_sample.rank()],axis=1)
_df.columns=['名前','得点','名前ランク','得点ランク']
_df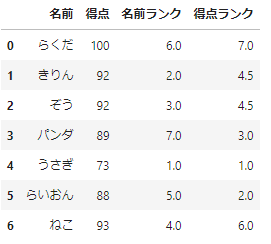
これでだいぶ見やすくなりましたね。よく見ると、得点が一番低いものが「1」になっていますね。これはデフォルトでは昇順でランク付けされるためです。降順にするときは、ascending=Falseを指定します。もう一つ、注意点があります。きりんとぞうの得点ランクが4.5になっています。これは、デフォルトでは同一値は平均順位となるためです。同一値をどのように扱うかは、methodで指定することができます。methodでは、「’average’, ‘max’, ‘min’, ‘first’」を指定することができます。
降順でのランク付け、同一値には’min’を指定してみましょう。
_df=pd.concat([df_sample,df_sample.rank(ascending=False,method='min')],axis=1)
_df.columns=['名前','得点','名前ランク','得点ランク']
_df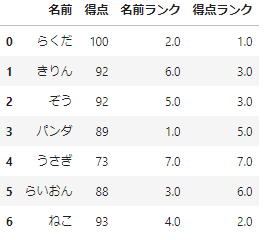
これでしっくりきましたね。名前ランクについては昇順、得点ランクについては降順にしたければ次のようにします。
df_sample['名前ランク']=df_sample['名前'].rank()
df_sample['得点ランク']=df_sample['得点'].rank(ascending=False,method='min')
df_sample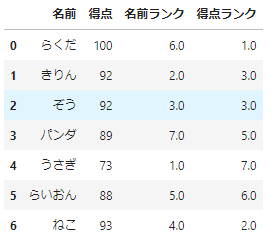
これで名前ランクは「あいうえお」順、得点ランクは「降順」で、同一順位は最小値とすることができました。
まとめ
いかがでしたか?データの順位を知りたい場面は結構ありますよね。そんなときにさくっとランク付けができると便利です。是非、ご活用ください。
▶ 縦持ちデータ/横持ちデータの変換に関する説明は次の記事をご覧ください。

コメント