
▶ 時系列データ分析を基本から学びたい場合は以下の記事からどうぞ。

- 時系列データの処理の仕方を知らない、または、基本から学びたい方
- 時系列データを扱ったことがあるが、体系的に整理できていないので、学びなおしたい方
はじめに
前回に引き続き、時系列データです。今回はStatsModelsを用いて時系列データの分析の仕方を学びましょう。まずは時系列データの周期性を確認する方法を基本から解説します。時系列データにはトレンド、周期変動、不規則変動の3つのパターンがあります。この3つの確認から始めましょう。
時系列データの3つのパターン
- トレンド
データの長期的な傾向をあらわします。時間の経過と主にデータの値が上昇していたり加工している場合に、「トレンドある」と表現します。 - 周期変動
周期変動があるデータは時間の経過に伴ってデータの値が上昇と下降を繰り返します。特に1年間の周期変動を季節変動といいます。 - 不規則変動
時間の経過と関係なくデータの値が変動することをいいます。
時系列データ分析
データはQiitaの記事で紹介されていた、金沢のアイスクリームの売上データを扱うことにしましょう。こちらでデータを提供してくれていました。
# ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# データの読み込み
data=pd.read_csv('icecream.csv')
data.head()
データはdate, earnings, temperatureの項目を持ちますが、よくみるとdateは月のデータとなっているようです。なので、earningsは月の売上、temperatureは月の平均気温でしょう。ここでデータ加工をしておきましょう。defaultではearningsもtemperatureもobjectとして読み込まれていたので、float型に変更しておきましょう。また、date部分をdatetime型にしてインデックスにする加工をします。
# 型の変更
data['earnings']=data['earnings'].astype('float')
data['temperature']=data['temperature'].astype('float')
# date部分をdatetime型に変換してインデックにセットする
data['date']=pd.to_datetime(data['date'])
data=data.set_index('date')
data.head()
時系列データの可視化
原系列
何も加工していない時系列データを原系列と呼びます。時系列データの目的は、「過去データに関する解釈」あるいは「未知データの予測」となります。実際には時系列データを加工して新しい系列(対数系列や階差系列や季節調整済み系列etc)にして、それを分析してモデルを構築することが多いですが、原系列も可視化して確認しておくとよいでしょう。
# 原系列の可視化
plt.figure(figsize=(16,8))
plt.plot(data['earnings'])
plt.grid()
plt.title('アイスクリームの売上推移',fontsize=18)
plt.xlabel('西暦',fontsize=15)
plt.ylabel('売上金額',fontsize=15)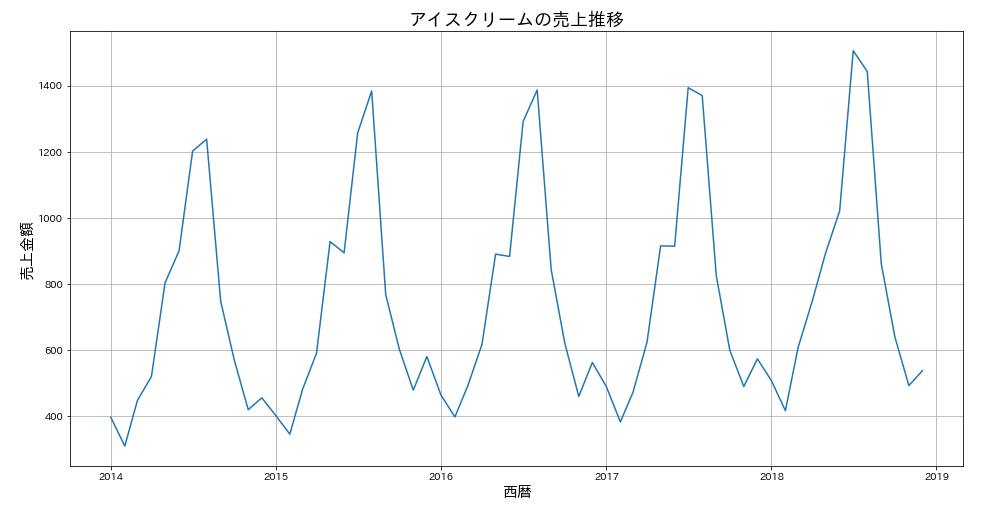
移動平均
次に移動平均をみていきましょう。ここでは、3か月、6か月、12か月の移動平均をプロットすることにしましょう。移動平均はrollingメソッドを使うと簡単にプロットすることができます。
▶ rolling()メソッドを使った移動平均の求め方は以下の記事をどうぞ。

plt.figure(figsize=(16,8))
plt.plot(data['earnings'], label = 'original')
plt.plot(data['earnings'].rolling(window=3).mean(), label='3m moving average')
plt.plot(data['earnings'].rolling(window=6).mean(), label='6m moving average')
plt.plot(data['earnings'].rolling(window=12).mean(), label='12m moving average')
plt.title('アイスクリームの売上推移 (+移動平均)',fontsize=18)
plt.xlabel('date',fontsize=15)
plt.ylabel('売上金額',fontsize=15)
plt.grid()
plt.legend()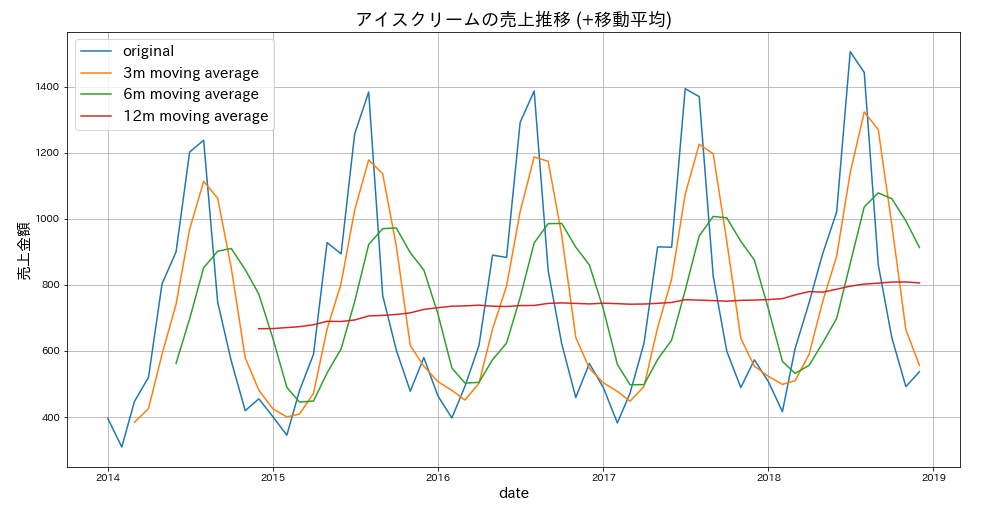
差分系列
差分系列は、1つ前との差で作られる系列です。これをプロットしておくと、大きな変化や周期性があるポイントを探しやすくなります。差分をとるにはdiff()メソッドを使います。
▶ diff()メソッドを使って差分を算出する方法は以下を参考にしてください。

# 差分系列の可視化
plt.figure(figsize=(16,8))
plt.plot(data['earnings'].diff())
plt.title('差分系列',fontsize=18)
plt.xlabel('Date',fontsize=15)
plt.ylabel('売上金額',fontsize=15)
plt.grid()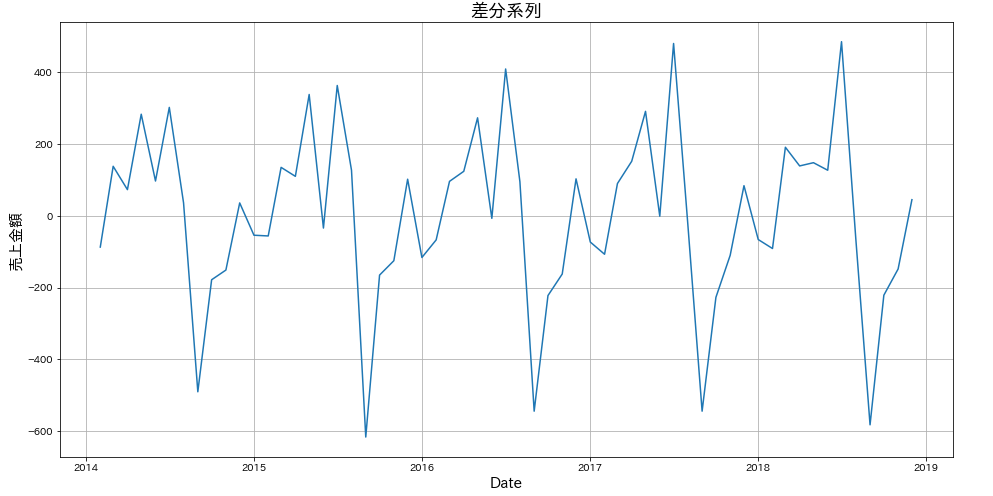
statsmodels
statsmodelsは、さまざまな統計モデルを推定したり、統計テストを実行したり、統計データを探索したりするための最高のPythonモジュールです。まずはライブラリの読み込み、データの準備からすすめていきましょう。
# ライブラリのインポート
import statsmodels.api as sm
statsmodelsのapiをインポートしています。ここではsmという名前としてあります。このstatsmodelsのtsa.seasonal_decompose()を利用すると、簡単に原系列を「トレンド」「季節変動」「不規則変動(残差)」に分けることができます。
周期性の確認
# 周期性の確認
res = sm.tsa.seasonal_decompose(data['earnings'],period=12,model="additive")
fig = res.plot()
fig.set_size_inches(16,8)
fig.tight_layout()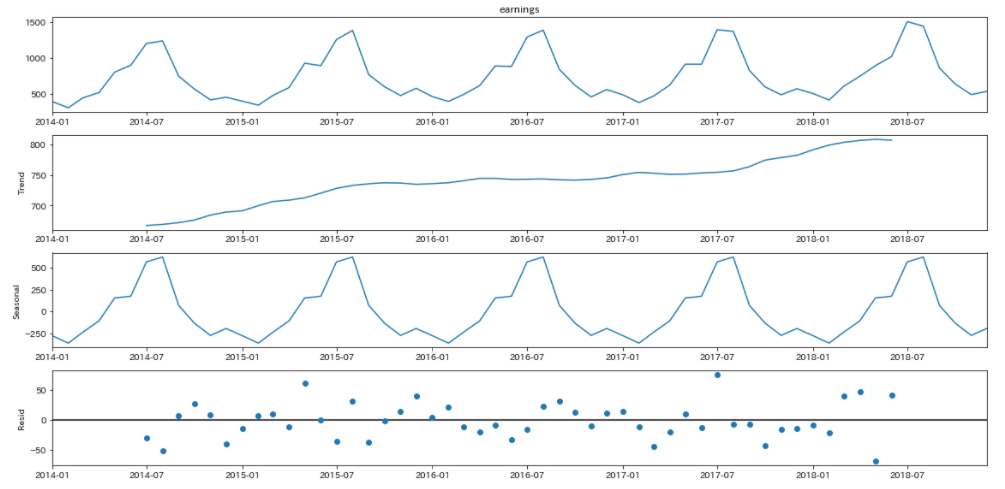
まとめ
いかがでしたか?今回は時系列データには3つのパターンがあることから説明をおこない、statsmodelsを使って、原系列を分解するところまでを解説しました。statsmodelsで一発で、トレンド、周期変動、不規則変動に分けられるのは便利ですね。
▶ データ分析を基本から学びたい場合は、以下の記事も参考にしてください。

コメント