
▶ データ分析を基本から学びたい場合は、以下の記事をご覧ください。

- pythonによるデータ分析を学び始めたばかりでpandasライブラリの基本を学びたい方
- DataFrameのデータ選択方法について基本を学びたい方
- 「DataFrameについての基本」を速習したい方
はじめに
今回はpandasのデータ構造の1つであるDataFrameのデータ選択方法を基本から解説していきます。DataFrameのデータ選択方法もいくつもあるため、1つずつ整理して理解を深めていきましょう。
DataFrameのデータ選択
辞書のイメージで
まず、辞書のイメージでデータを選択する方法をご紹介します。Seriesのときには、見出し(index)を指定してデータを選択しました。DataFrameでは列方向の見出し(columns)を使ってデータを選択することができます。各列がSeriesオブジェクトとなっていて、これが列方向の見出し(columns)と対応しています。
例をみてみましょう。まずはサンプルのDataFrameを作りましょう。
▶ pandasのデータ構造やDataFrameの作り方を学ぶ場合は以下の記事をどうぞ。

# DataFrameの列となるSeriesを作成
animals=pd.Series(['らくだ','ねこ','きりん','しまうま','らいおん'])
zoos=pd.Series(['うえの','うえの','あさひやま','ズーラシア','こどもどうぶつえん'])
ages=pd.Series([8,4,2,6,1])
# DataFrameを作成
animal_df=pd.DataFrame({'なまえ':animals,'どうぶつえん':zoos,'年齢':ages})
animal_dfこのコードで次のサンプルデータができます。
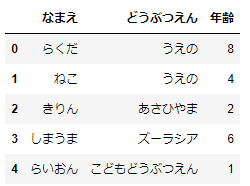
このDataFrameから「どうぶつえん」のデータのみを抽出してみましょう。DataFrameの作り方からもわかるように、DataFrameはSeriesの集まりと考えることができます。辞書型と同じように角括弧でcolumns名を指定することで、Seriesを抽出できます。
animal_df['どうぶつえん']0 うえの
1 うえの
2 あさひやま
3 ズーラシア
4 こどもどうぶつえん
Name: どうぶつえん, dtype: object2次元配列と同じように
次に2次元配列として考えてみましょう。この場合は、Seriesのところでも紹介したように、loc属性、iloc属性を使います。これは別の記事にまとめてあるので、これを参照してください。
▶ loc、iloc属性を使ったデータ選択は以下の記事をご覧ください。

その他の規則
「辞書のイメージ」のところで、列を参照する方法を扱いましたが、スライスは「行」を参照します。これもややこしい部分ですが、はじめにこういうルールとなっていることを注意して学んでおけば大丈夫です。この動きを確認しておきましょう。
animal_df[1:4]この結果は次のようになります。

行の見出し(index)が数字の場合もみておきましょう。
# 行のインデックスを文字列にする
animal_df2=animal_df.copy()
animal_df2.index=['どうぶつ1','どうぶつ2','どうぶつ3','どうぶつ4','どうぶつ5']
animal_df2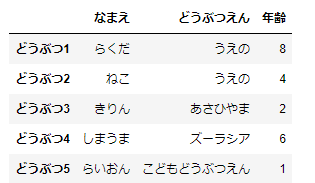
このDataFrameでスライスをしてみましょう。
animal_df2['どうぶつ2':'どうぶつ5']この結果がどうなるか想像できますか?

Seriesのときに紹介した注意事項と同じように、スライスは見出し(index)が数字の時と文字列の時で挙動が違うので注意しましょう。数字の時は「:」のあとの見出し(数字)を含まない、文字列のときは「:」のあとの見出し(文字列)を含む、となるので注意してください。
最後にマスキング処理ですが、これは次の形となります。dfというDataFrameがあるとして、
df[条件式]の形でデータを抽出することができます。この場合も列に対してではなく、行に対して解釈されます。一つだけ例を見ておきましょう。
animal_df[animal_df['年齢']>3]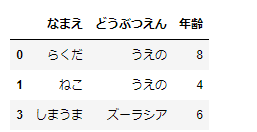
まとめ
いかがでしたか?今回はDataFrameのデータ選択方法についてご紹介しました。
▶ Seriesのデータ選択はこちらの記事をお読みください。

▶ データ分析を基本から学びたい場合は、以下の記事をごらんください。
コメント