
はじめに
今回も、前回に引き続きスクレイピングを扱います。前回同様に「requests」と「BeautifulSoup」というライブラリを使います。今回は、取得したHTMLを解析する際の条件指定をselect( )を使ってやってみましょう。
準備
「requests」や「BeautifulSoup」のインストール、インポートなどは前回の記事に掲載しているので、そちらを参照してください。

BeautifulSoupを使って情報を抽出する
前回の記事に掲載している、ページを指定してHTMLを取得し、BeautifulSoupで解析した結果を「soup」という変数に格納している状態とします。
今回はselect( )による条件指定をしますが、find( )系にfind_all( )とfind( )があるように、select( )系にもselect( )とselect_one( )があります。これらは条件に合致したものをすべて返すか、一つ返すかの違いなので、select( )の場合で説明をします。
select( )を使った解析の基本
まずはタイトルを取得してみましょう。select( )を使った解析は次のような書式となります。
soup.select(CSSセレクタ)CSSセレクタは、単純なタグやclass、idなどは直接指定すればよいですが、複雑なものを指定する場合は、Chromeのデベロッパーツールを使うと簡単におこなうことができます。
たとえば、このブログのトップページの「分析をもっと身近に。データを生かすお手伝いをします。」の部分を取得することにしましょう。

HTMLのソースを見ないと、この部分をどのように指定してよいかわかりません。HTMLのソースを見ても、HTMLに詳しくなければ、その指定は難しいかもしれません。でも、心配いらないんです。ページにアクセスして、Chromeのデベロッパーツールを開いてください。
※ショートカットで「F12」あるいは「Ctrl+Shift+i」を押すと立ち上がります。
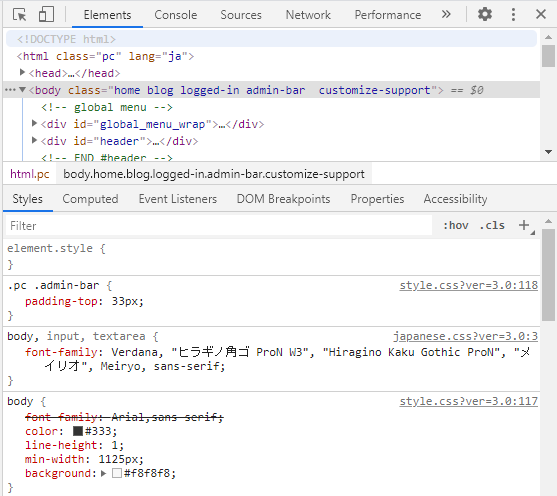
こんな画面が立ち上がります。この画面の左上にある、「Select an element in the page to inspect it Ctrl + Shift +C」を選択します。

これを選択した状態で、ページの情報を取得したい部分にマウスを合わせます。今回はロゴの下にある「分析をもっと身近に。データを生かすお手伝いをします。」です。すると、次のような表示変わります。

図の左上に、指定するべきCSSセレクタが表示されていますが、これを直接打ち込まなくても、コピーする方法があります。(いまはマウスを合わせた状出たいですが)次にクリックをします。すると、デベロッパーツール上で対象の箇所がハイライトされます。
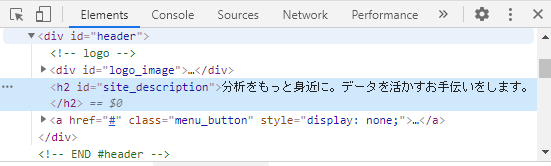
このハイライトされた箇所で右クリックをして、Copy→Copy selectorをクリックします。すると、クリップボードにCSSセレクタがコピーされます。
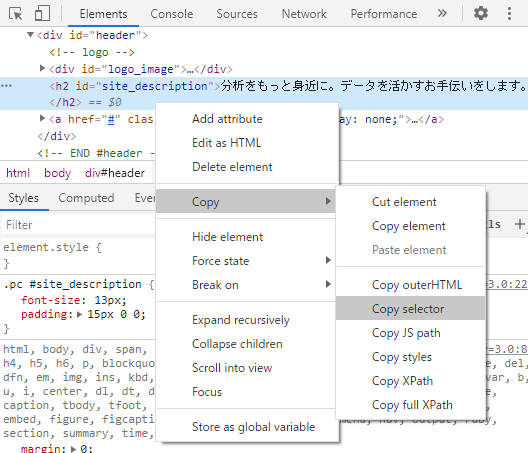
では、select( )とCSSセレクタを使ってこの部分を抜き出してみましょう。既にクリップボードにCSSセレクタがコピーされているので、soup.select( )と書いて、( )の中身にCSSセレクタをペーストすると次のように記述できます。
soup.select('#site_description')これを実行すると、次のようになります。
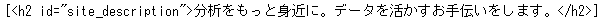
ちゃんと取得できました。毎回、このような手順を踏む必要はありませんが、どのように条件指定すればよいかわからないときなどは、このようにして条件指定のヒントを得るのもよい方法だと思います。
select( )による条件指定
find_all( )でやったのとおなじようなことをselect( )でも試してみましょう。まずはタイトルタグです。これは、まったく同じですね。
soup.select('title')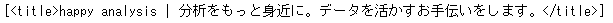
これはfind_all( )のときに、soup.find_all(name=’title’)を省略してsoup.find_all(‘title’)と記述した場合と同じ書式ですね。但し、select( )の場合は、nameという引数があるわけではないので、name=’title’という書き方はできません。
次にaタグの中で、class属性が「home_menu」であるものを抽出してみましょう。
soup.select('a.home_menu')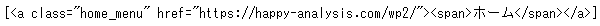
まず、class属性の値を指定するには、「.」に続けてclass属性の値を記述します。今回は、classが「home_menu」であるものを指定したいので、「.home_menu」となります。あるタグの中で、class属性を指定したいなら、タグの後にclass属性の指定を続ければよいです。そのため、aタグでclass属性が「home_menu」であるものは、「a.home_menu」となります。
次に複数のclass属性を指定する場合です。liタグ配下で、classが「clearfix num1 type1」であるものに完全一致させるには、次のように記述します。
soup.select('li.clearfix.num1.type1')
部分一致にしたいときんは、「,」カンマで区切って次のように記述します。
soup.select('li.clearfix.num1,li.clearfix.num2')
idの場合は、「#」にidの属性値をつけて指定します。ulタグの中で、idがmenu-pythonであるものを指定する場合は、次のようにします。
soup.select('ul#menu-python')
最後に正規表現を用いたhref属性の指定を見ておきましょう。href属性を指定する場合の基本形は以下となります。
soup.select([href='属性値'])但し、この指定では完全一致になります。少し、使いにくいですね。そこで正規表現を使います。検索タイプごとに次のような記述方法があります。
| 検索タイプ | 書式 |
| 前方一致 | [href^=”属性値の先頭部分”] |
| 後方一致 | [href$=”属性値の後尾部分”] |
| あいまい検索 | [href*=”属性値の一部”] |
あいまい検索を使って条件指定をしてみましょう。
soup.select('a[href*="python-topic-summary-basic"]')
このようにタグの指定がある場合は、[hrefの記述]の前に指定すればOKです。
まとめ
いかがでしたか?2回にわたって、Webスクレイピングを扱いました。基本的にはrequestsでHTMLを取得して、Beautifulsoupで解析したものを変数に入れる。このBeautifulSoupオブジェクトに対して、find_all( )やselect( )で条件指定をして、必要な条件を抽出します。Web上から必要な情報を取得できるようによく復習しておきましょう。
コメント