
はじめに
今回はpandas_profilingについてご紹介します。データを取得したら、まず探索的データ解析(EDA:Exploratory data analysis)をおこないますよね。これは、データの特徴を探求して構造を理解することを目的としたプロセスです。これを自動化してくれるのがpandas_profiligです。さっそく見ていきましょう。
データの準備
今回はオープンデータを使ってみましょう。以前にもご紹介しましたが、東京都が運営している「新型コロナウィルス感染症対策サイト」で公開されている「陽性者の属性」のデータを使ってみましょう。このデータの取得方法は以下の記事で簡単に触れています。

データをcsvでダウンロードしておきましょう。このデータをpandasで読み込んでおきましょう。
# ライブラリのインポート
import pandas as pd
import pandas_profiling
import matplotlib.pyplot as plt
import japanize_matplotlib
%matplotlib inline
# データの読み込み
data=pd.read_csv('data/tokyo_covid19_20200913.csv')
data.head()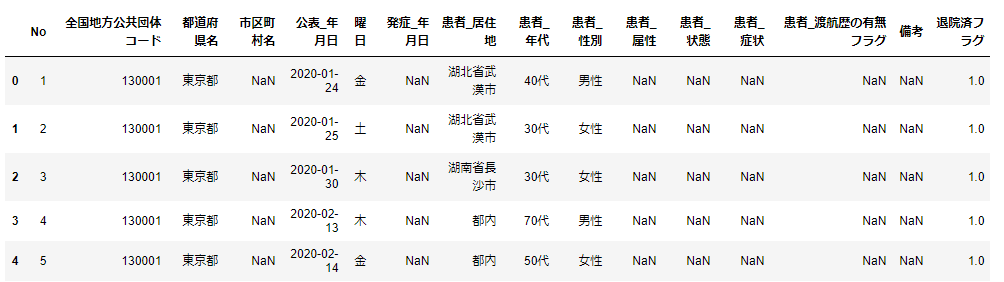
データはちゃんと取り込めているようですね。
pandas_profiling
早速、pandas_profilingを試してみましょう。まだインストールしていない場合は、以下のコマンドでインストールを済ませてしまいましょう。
# ライブラリのインストール
pip install pandas-profilingこれで準備完了です。
# ライブラリのインポート
import pandas_profiling
# EDAの実行
data.profile_report(title='東京都の新型コロナウィルス感染者について')この1行でEDAが実行され結果が表示されます。もしうまくいかない場合は、次を試してみてください。環境によってはこちらのコードしか動かない場合もあります。
pandas_profiling.ProfileReport(data)これでもうまくいかない場合は、エラーメッセージをよくみてください。きっと、何かのパッケージのバージョンが古いのでアップグレードするように、などのメッセージが出ているはずです。
EDAの結果は次のようにするとHTMLとして出力することができます。この方が結果を見やすいので、私はHTMLに出力するようにしています。
# HTMLに出力
profile=data.profile_report(title='東京都の新型コロナウィルス感染者について')
profile.to_file(output_file="tokyo_covid19.html")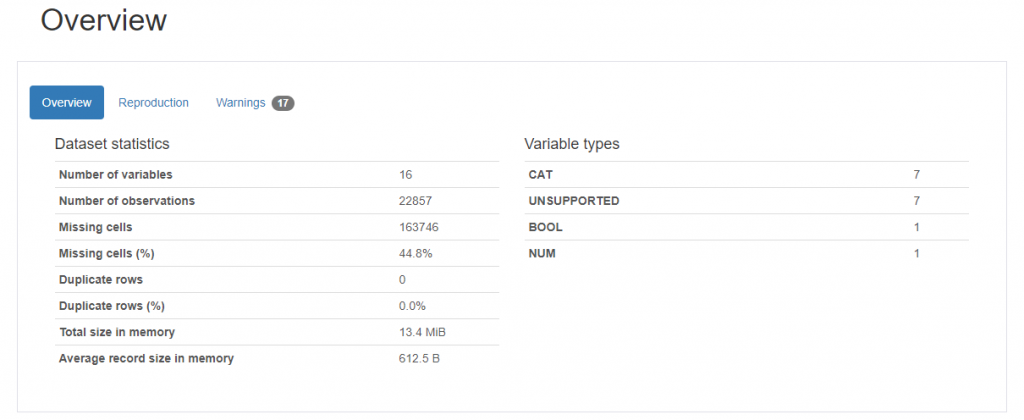
これをみるだけでも、16個の変数があって、レコード数は22857であることや、変数の型がわかります。さらに、各変数ごとの詳細な結果もあります。
患者年代をみてみましょう。

若い世代に陽性者が多いことがわかります。20代・30代・40代・50代・60代の順となっていますね。これは単純に「若い」ということが理由なのか、「若い」人の行動範囲によるものなのか、はわかりませんが、このように各項目音特徴をみていくと、今後のデータ分析をするうえでの「仮説」をたてることができます。
まとめ
いかがでしたか?このブログでも何度か使っているので、いまさらのご紹介ですが、実は新しいPCの環境で、pandas_profilingが動かずに調べたこともあったので、記録に残しておきました。
▶ データ分析の流れを確認したい場合は以下の記事をどうぞ

コメント