
はじめに
今回はテキストデータのカテゴリ化を扱います。たとえば、都道府県ごとにコードを割り振りたいなど、テキストデータをカテゴリ化する場面は意外に多いですよね。テキストデータのカテゴリ化は、一度map()を紹介した投稿の中で扱っていますが、今回あらためてご紹介します。

サンプルデータの作成
では、都道府県をカテゴリ化することにして、以下のコードでサンプルデータを作りましょう。
# ライブラリのインポート
import pandas as pd
# サンプルデータの作成
df_sample=pd.DataFrame(
{'なまえ':['らくだ','らいおん','ぱんだ','ねこ','いぬ','いのしし','うま','かば'],
'都道府県':['神奈川県','東京都','東京都','神奈川県','北海道','埼玉県','北海道','埼玉県']})
df_sample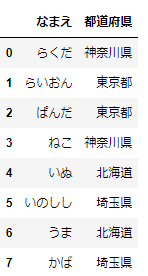
どうぶつたちの住んでいる都道府県のデータです。この都道府県をコードで表すことにしましょう。
テキストデータのカテゴリ化
早速やってみます。ここに出てくる都道府県は、「神奈川県」」「東京都」「北海道」「埼玉県」ですね。それぞれにつぎのようにコードを振ることにしましょう。
北海道:001
東京都:002
神奈川県:003
埼玉県:004
都道府県は「道」や「県」「都」などまちまちで、さらに都道府県名の文字列の長さもことなります。でも、はじめの3文字を抜き取れば、ユニークになりますね。そこで、次のように処理することができます。
df_code=pd.concat([df_sample,df_sample['都道府県'].map({
'北海道':'001',
'東京都':'002',
'神奈川県':'003',
'埼玉県':'004'
})],axis=1)
df_code.columns=['なまえ','都道府県','コード']
df_code[['コード','都道府県','なまえ']].sort_values(by='コード')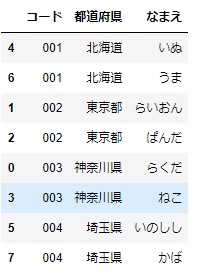
都道府県をコードに変換する処理は、map()と辞書を使うことで実現しています。もとのデータフレームに、都道府県をもとに作成したシリーズを連結する処理をするだけで簡単につくれますね!
まとめ
短くて簡単なコードですが、知らないとなかなかかけないこともありますよね。テキストデータをカテゴリ化したい場面は、意外に多いと思うので、おさえておくとよいでしょう。
コメント