
はじめに
今回も東京都のコロナウィルス感染者数のデータを扱うことにしましょう。今回はpandasを使うことにします。pandas_profilingを使ってデータを眺めて、次にいくつかの描画をすることにします。
データの取得の仕方については過去の投稿を参考にしてください。

データを読み込む
まずライブラリを読み込み、ざっとデータを確認してみましょう。
# ライブラリのインポート
import numpy as np
import pandas as pd
import pandas_profiling
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
import pandas_profiling
# 初期設定
sns.set_style("whitegrid", {'grid.linestyle': '--'})
%matplotlib inline次にデータを読み込みます。私は、’20200505_patients.csv’というファイル名でデータを保存しています。
_data=pd.read_csv('20200505_patients.csv')まず取り込んだデータの行数・列数を確認してみましょう。
_data.shape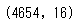
4654行・16列のデータであることがわかります。実際にどんなデータなのかを確認してみます。先頭の3行をみてみましょう。
_data.head(3)
患者_属性や患者_状態など、NaNとなっているデータがあります。各列のデータ型や有効データ数などをみてみましょう。
_data.info()
浮動小数点数型が8つ、整数型が2つ、カテゴリ型が6つですね。ただ欠損値が多いです。Non-Null Countをみると0 non-nullとなっている項目が6つあります。これらは全くデータがないので削除してしまってよいでしょう。「全国地方公共団体コード」も使いません。今回のデータは東京都とわかっているので、「都道府県名」の列も削除してしまいましょう。また、「公表_年月日」はobject型になっているので、datetime型に変換することにします。
data=_data[['No','公表_年月日', '曜日','患者_居住地', '患者_年代', '患者_性別','退院済フラグ']]
data['公表_年月日']=pd.to_datetime(data['公表_年月日'])
data.head()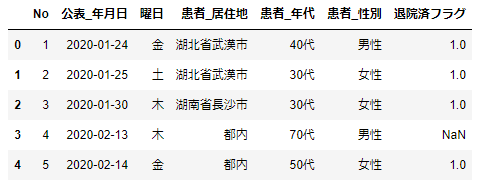
このデータを眺めていくことにしましょう。
データを眺める
ここでは、pandas_profilingを使ってデータの概要を把握していきましょう。
report=data.profile_report()
report- 公表_年月日
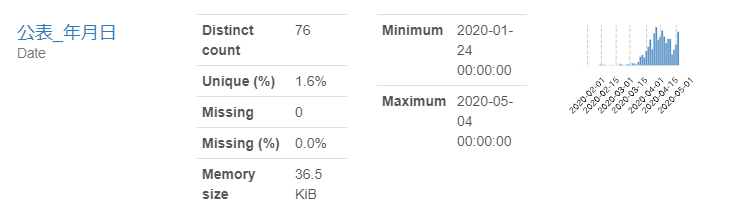
ユニークな値は76あります。前回、ヒストグラムを描きましたが、上記のコードだけでヒストグラムを確認できます。「Toggle detail」のボタンを押してみてください。
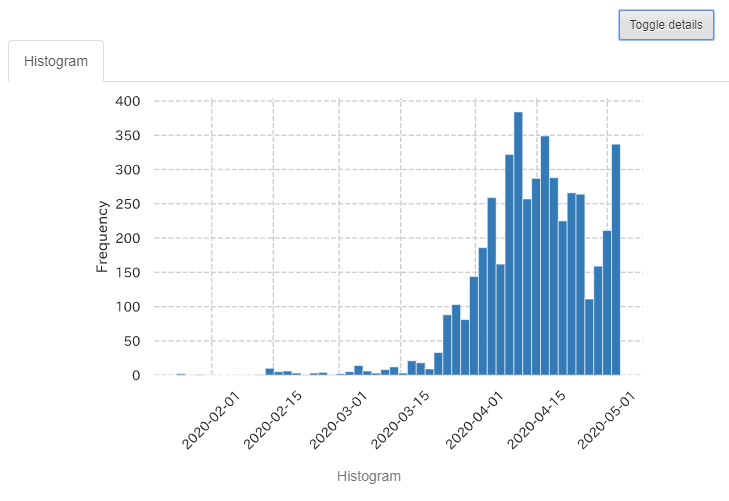
- 曜日
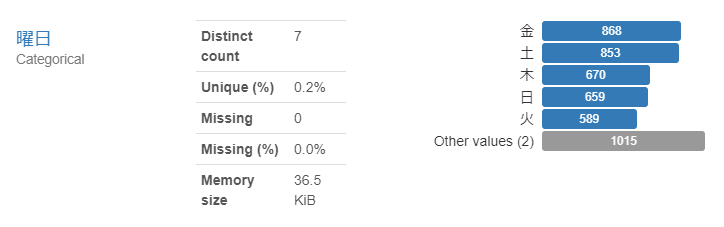
ユニークな値が7つあります。これは日曜日・月曜日・・土曜日の7つですね。金曜日と土曜日の感染者数が多そうです。ここでも「Toggle detail」を押してみましょう。
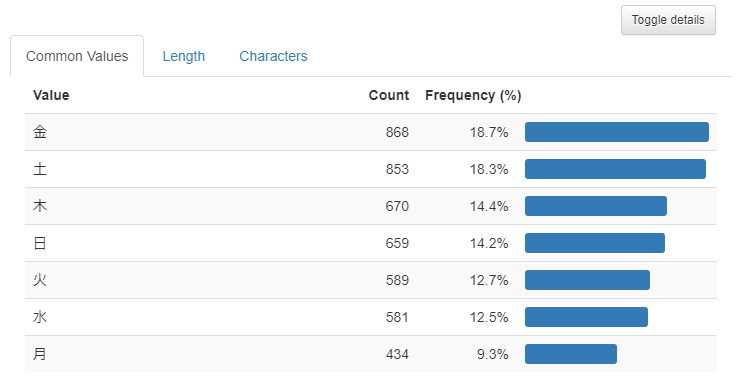
月曜日の感染者数が極端に少ないですね。これは、検査結果は即日わかるわけではなく、日曜日の検査数は少ないのかもしれないですね。
- 患者_年代
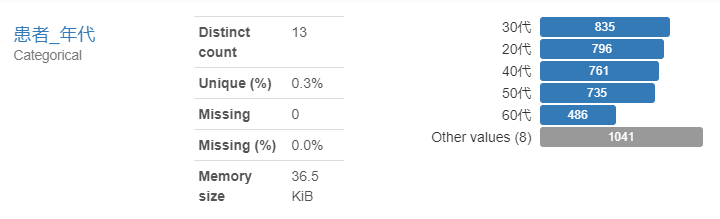
30代の患者が一番多く、次いで20代の患者が多いようです。コロナウィルスによる死者は高齢者が多い、という報道から、感染者数について誤認識してました。若い人たちの感染が多いようです。ここでも「Toggle detail」をみてみましょう。
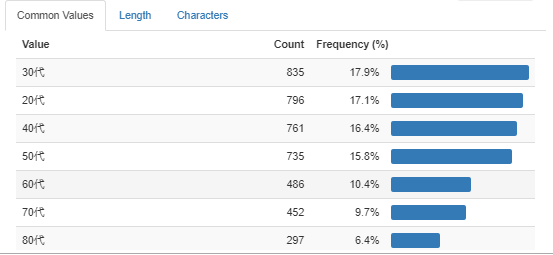
さらに詳しく見ると、30代、20代に次いで40代、50代の感染者数が多いです。これは働く世代の感染が多いようですね。報道は60代、70代は感染者数の割には、死亡者数が多い、ということなのですね。
- 患者_性別
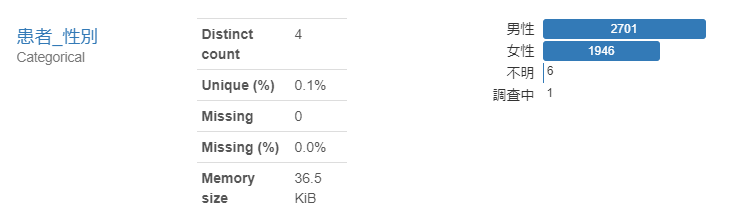
男性の患者数が多いようです。割合まで見るには、「Toggle detail」をみるとよいです。
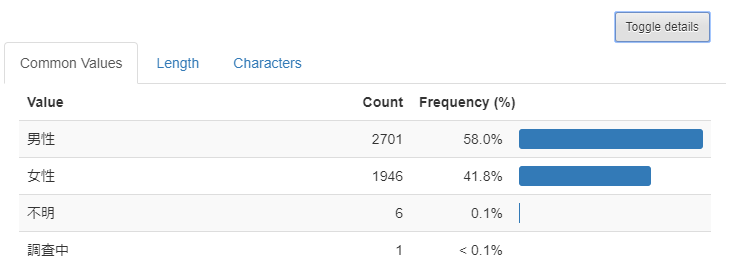
男性58.0%に対して、女性41.8%です。数件ですが、不明や調査中というのもあるのですね。
- 退院済フラグ
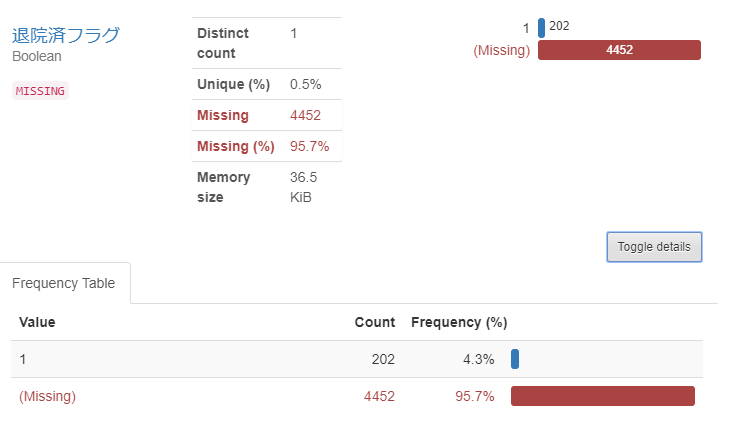
最後に退院済みフラグです。退院済みは感染者に対してわずか4.3%です。これは情報が更新されていないだけなのか、そもそも感染者といっても入院しているとは限らないのかもしれません。
気になったところをさらにみる
男女別に感染者数推移をみる
ここでは、性別の感染者数の推移と、年代別の感染者数の推移をみてみましょう。4月以降のデータのみ切り出してプロットしてみます。
# 公表_年月日、性別でグループ化して集計
data_sex=data.groupby(['公表_年月日','患者_性別']).agg({'No':'count'}).reset_index()
data_sex.columns=['年月日','性別','count']
# 公表日のフォーマット調整
data_sex['公表日']=data_sex['年月日'].dt.strftime('%m-%d')
# 描画
plt.figure(figsize=(18,8))
sns.barplot('公表日','count',data=data_sex[69:].query('(性別=="男性")|(性別=="女性")'),hue='性別',hue_order=['男性','女性'])
plt.xticks(rotation=90)
plt.legend(loc='upper right',title='性別')
plt.title('東京都の男女別コロナウィルス感染者数',fontsize=18)
plt.xlabel('公表日',fontsize=15)
plt.ylabel('感染者数(人)',fontsize=15)
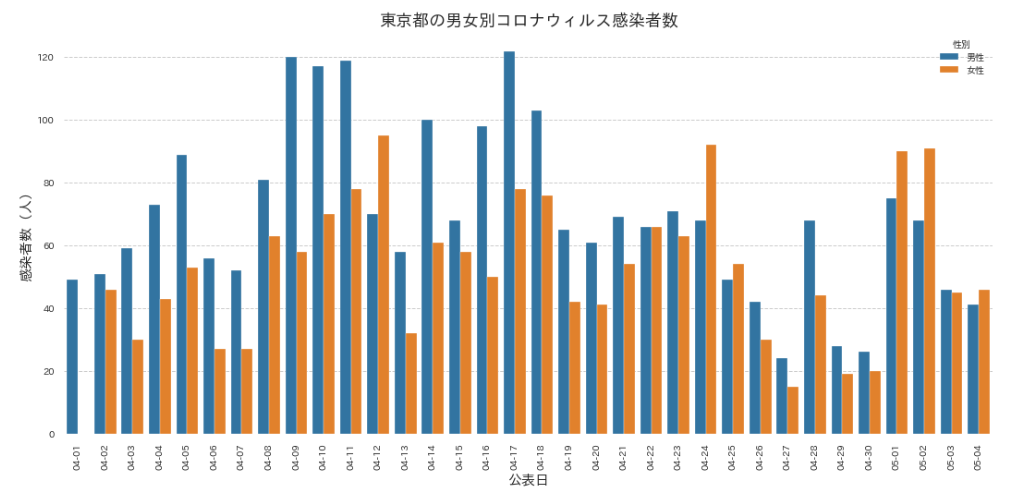
累計で、男性の患者数の方が多いですが、日次推移をみていると直近では女性の患者数が多くなっていますね。
年代別・男女別にみる
データを眺めていて20代・30代の感染者数が多いことがわかりました。さらに、男女別でみるとどうなるでしょうか?
data_gen_sex=data.groupby(['患者_年代','患者_性別']).agg({'No':'count'}).reset_index()
data_gen_sex.columns=['年代','性別','count']
data_gen_sex.sort_values(by='count',ascending=False).head(10).reset_index(drop=True)
年代別・男女別でTop10を表示してみました。一番多いのは「40代男性」、次いで、「30代男性」「50代男性」の順でした。ちゃんとニュースを見ていないだけかもしれませんが、印象とだいぶ違いました。
まとめ
身近にあるオープンデータを集計するだけでも、いろんな気づきがあります。今回は東京都のデータを使いましたが、政府統計の窓口e-Statなどから気になるデータを引っ張ってきても面白いかもしれません。
コメント