
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ matplotlibによる可視化を基本から解説しています。以下の投稿も合わせてご覧ください。

はじめに
今回はseabornのカテゴリ変数に関するプロットをまとめて紹介します。既に紹介したものを含めてまとめて整理しましょう。普段見慣れないプロットもありますが、カテゴリ変数を可視化するうえで非常に便利です。seabornでは簡単に描画できるので是非身につけましょう。
カテゴリ変数に関するプロット
カテゴリ変数に関するプロットだけでもいろんなものが用意されています。早速見ていきましょう。今回もseabornにあらかじめ準備されている学習用データセットである「taxis」を使います。
# ライブラリのインポート
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
# データセットの読み込み
df = sns.load_dataset('taxis')
df.head()
棒グラフ(barplot)
まずは棒グラフから見ていきましょう。既にmatplotlibで棒グラフを扱っていますが、plt.bar(x, height)ではheightに既に計算された値を指定します。それに対して、seabornの棒グラフでは描画の時に指定した計算を実行してくれます。書式は次のようになります。
xにカテゴリ変数、yに棒グラムの高さを表す際に使う変数、estimatorではyで指定した変数にどのような計算を適用するかを指定します。defaultでは平均(np.mean)となっています。やってみましょう。
# 棒グラフ:平均
sns.barplot(x='dropoff_borough', y='tip', data=df,estimator=np.mean,ci=False)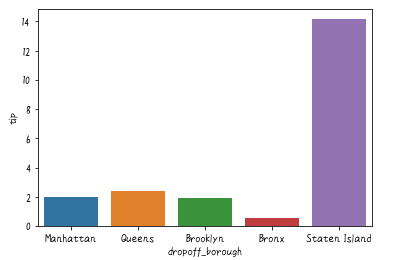
boroughは「自治区」という意味らしいです。なのでタクシーの降車エリアごとのチップの平均額ですね。ciという引数は信頼区間を表します。非表示にするにはci=Falseとします。estimatorはdefaultで平均なのでestimator=np.meanは省略しても構いません。最大値で棒グラフを描くには次のようにします。
# 棒グラフ:最大値
sns.barplot(x='dropoff_borough', y='tip', data=df,estimator=np.max,ci=False)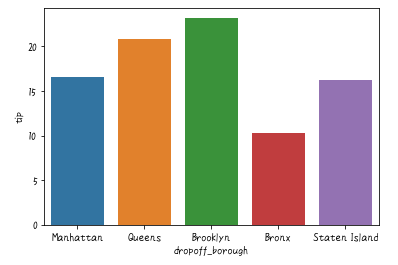
カウントプロット(countplot)
次にカウントプロットです。これはカテゴリ変数の数を数えてプロットしてくれます。書式は以下となります。
xに数を数えるカテゴリ変数を指定するだけです。やってみましょう。
# dropoff_boroughの値ごとの数
sns.countplot('dropoff_borough',data=df)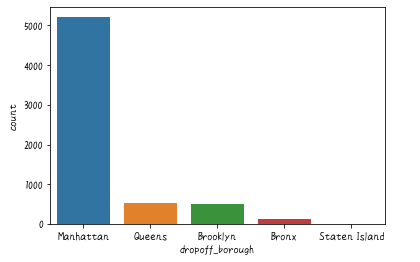
箱ひげ図(boxplot)
次に箱ひげ図です。既にmatplotlibで扱っていますが、seabornでも描くことができます。seabornでは色付けされるので、みやすいグラフになります。書式は以下となります。
xにカテゴリ変数、yに分布を見たい変数を指定します。すると、カテゴリ変数ごとにyで指定した変数の分布を箱ひげ図としてプロットしてくれます。早速やってみましょう。
# 箱ひげ図
sns.boxplot('dropoff_borough','tip', data=df)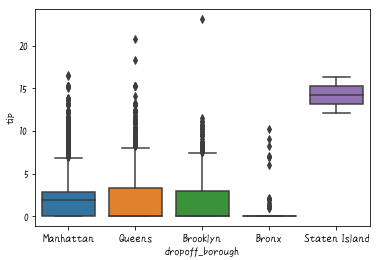
簡単ですね。完全に好みの問題ですが、少し、色がきつく感じませんか?paletteでcolor mapを指定することができます。pastelを指定すると以下のような感じになります。
# 箱ひげ図:paletteを指定
sns.boxplot('dropoff_borough','tip', data=df, palette='pastel')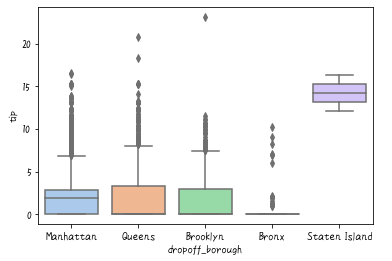
箱ひげ図は実際のデータの分布まではわかりません。そこで次に紹介するバイオリンプロットがあります。
バイオリンプロット(violinplot)
バイオリンプロットでは箱ひげ図では確認できなかった分布まで確認することができます。次の書式となります。
x, y は箱ひげ図の場合と同じですね。早速やってみましょう。
# バイオリンプロット
sns.violinplot('dropoff_borough', 'tip', data=df, palette='pastel')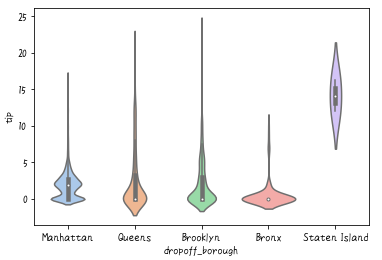
このように箱ひげ図ではわからなかった分布がわかります。どの値のデータが多いのかが視覚的にわかりますね。ただ、このプロットは「正規化」されているので注意してください。そのため、データの数まではわかりません。横のバイオリンとは比較できないことに注意が必要です。
これを解決するのが次に紹介するswarmplotです。
swarmplot
最後に紹介するのがswarmplotです。見慣れないプロットかもしれませんが、先ほどのバイオリンプロットではデータの数までは比較できない、という問題を解決したプロットになります。次の書式になります。
引数については、箱ひげ図やバイオリンプロットと同じです。早速試してみましょう。
# swarmplot
sns.swarmplot(x='dropoff_borough', y='tip', data=df, palette='pastel')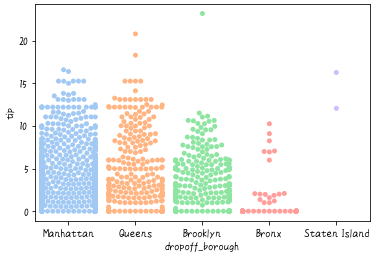
このようにデータの個数まで視覚的に捉えることができます。ただ、このプロットは横幅が十分ではなく分布がよくわかりませんね。少し横幅を広げてみましょう。
# swarmplot:描画領域を広げて
fig, ax =plt.subplots(figsize=(30,8))
sns.swarmplot(x='dropoff_borough', y='tip', data=df, palette='pastel',ax=ax)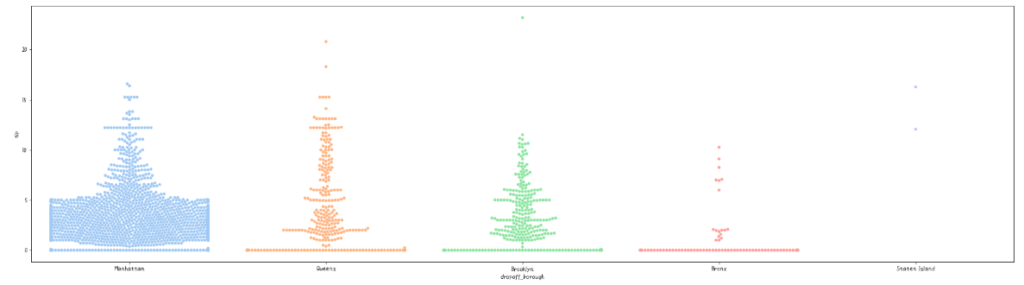
描画領域を広げてみましたが、まだ足りてないですね。Manhattanではまだプロットしきれてないですね。このようなときには、横幅を十分にとるか、あるいは、バイオリンプロットと併用して、バイオリンプロットで分布を確認、swarmplotでデータの数を確認するとよいでしょう。
まとめ
今回はカテゴリ変数に関するプロットをまとめて紹介しました。今回紹介したプロットは、どれもよく使うものなのです。swarmplotは分布もデータの数も視覚的にわかってよいですね。ただ、データが多いと描画にかなり時間もかかるので、使い分けるとよいでしょう。
コメント