
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ Numpyの基本を解説しています。過去の記事はこちらからどうぞ。


はじめに
今回はndarrayを条件に応じて処理する方法を扱います。ndarray[条件]のように条件を満たすデータを抽出方法やwhereを使って条件に応じて処理をおこなう方法を基本から解説します。また「すべての要素が条件を満たす」「要素のうち少なくとも1つが条件を満たす」行・列の抽出方法についても解説します。
条件を満たすデータを抽出する
ndarrayから条件を満たすデータを抽出する場合は、以下の書式となる。
角括弧[ ]の中に条件式をいれるだけですね。条件式は各要素について条件判定をおこなった結果である論理値(True/False)配列となります。つまり角括弧の中に同じ形状の論理値の配列を指定していることになります。この結果、TRUEと判定された要素のみが返されます。やってみましょう。
import numpy as np
# ndarrayのサンプルデータを作成
np.random.seed(0)
sample_array = np.random.randint(0,10,size=(3,4))
sample_array
このndarrayに条件を指定してデータを抽出してみましょう。
# 条件を指定してデータを抽出
sample_array[sample_array>3]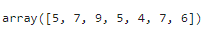
このようにndarrayが多次元配列であっても返されるのは一次元配列になります。Trueと判定された要素のみが返されるので、もとの配列の形状は保てないですもんね。
条件を満たす行・列を抽出する
すべての要素が条件を満たすかどうかを判定するのはall(), 要素のうち少なくとも1つが条件を満たすかどうかを判定するのはany()となります。これは次のような書式となります。
np.all(), np.any()はそれぞれaxisの指定を行えば行(axis=1)・列(axis=0)ごとの判定をすることができます。この判定結果を用いることで、条件を満たす行・列の抽出をすることができます。
1つずつ見ていきましょう。まずはnp.all()です。
np.all()
print('sample_array')
print(sample_array)
print()
print('要素がすべて2より大きいかどうかを判定')
print(np.all(sample_array>2))
print()
print('列ごとに各列の要素がすべて2より大きいかどうかを判定')
print(np.all(sample_array>2,axis=0))
print()
print('行ごとに各行の要素がすべて2より大きいかどうかを判定')
print(np.all(sample_array>2,axis=1))
「要素がすべて2より大きいかどうかの判定」の答えはTrueかFalseのどちらか1つだけですね。こんかいは0や2を含むのでFalseとなります。
次に「各列の要素がすべて2より大きいかどうかの判定」の答えは列の数だけTrue/Falseがあります。3×4の行列なので4つの論理値が返ってきています。
最後に「各行の要素がすべて2より大きいかどうかの判定」の答えは行の数だけTrue/Falseがあります。3×4の行列なので3つの論理理が返ってきています。
これらの判定結果を使って行のみ・列のみのデータを抽出してみましょう。まずは「列のすべての要素が2より大きい」ものからみていきましょう。
# 要素がすべて2より大きい列を抽出
sample_array[:,np.all(sample_array>2,axis=0)]
先ほど確認した列の要素に関する判定をした条件を使います。列を抽出するのでndarray[:, 条件]とします。
次に「行のすべての要素が2より大きい」ものも確認しておきましょう。
# 要素がすべて2より大きい行を抽出
sample_array[np.all(sample_array>2,axis=1)]先ほど確認した行の要素に関する判定をした条件を使います。行を抽出するのでndarray[条件]とします。
np.any()
print('sample_array')
print(sample_array)
print()
print('列ごとに各列の要素のうち少なくとも1つが6より大きいかどうかを判定')
print(np.any(sample_array>6,axis=0))
print()
print('行ごとに各行の要素のうち少なくとも1つが6より大きいかどうかを判定')
print(np.any(sample_array>6,axis=1))
np.all()の場合と同様なので説明は割愛します。実際に対象の行を取り出すコードも確認しておきましょう。
# 少なくとも1つの要素が6より大きい列を抽出
sample_array[:,np.any(sample_array>6,axis=0)]
# 少なくとも1つの要素6より大きい行を抽出
sample_array[np.any(sample_array>6,axis=1)]
条件に応じた処理をする
np.where()
条件を満たすデータの抽出をすることもできますが、np.where()は条件に応じた処理をするのに使われることが圧倒的に多いです。以下を覚えておけばよいでしょう。
この構文は条件を満たす(True)のものはaに、条件を満たさない(False)のものはbに置き換えることができます。やってみましょう。
# np.where()
np.where(sample_array>2,3,0)
2より大きい値は3に、それ以外の数字は0に置き換わってますね!
np.clip()
np.clip()はa_min以下のものはa_minに、a_max以上のものはa_maxとすることができます。書式は以下のようになります。
これも試しておきましょう。
# 4と6でクリップする
np.clip(sample_array, 4,6)
4以下のものは4に、6以上のものは6に、それ以外のものはそのままの値を保ちます。
まとめ
今回はndarrayを条件に応じて処理する方法を扱いました。まずは条件を満たすデータの抽出方法を基本から解説しました。次にすべての要素が条件を満たすnp.all()、少なくとも一つの要素が条件を満たすnp.any()やこれらを行ごと・列ごとに適用して判定させたり、この判定結果を使ったデータの抽出についてコードで確認しました。最後に条件に応じた処理の例としてnp.where()やnp.clip()を解説しました。この辺は機械学習の前処理でもよく出てくる処理なので、しっかり身に着けておきましょう。
コメント