
- Pythonを始めたばかりで基本から学びたい方
- Pythonの基本的な部分を速習してまずは全体像を把握しておきたい方
▶ 初学者向けにデータ分析に関する記事を書いています

はじめに
今回はデータフレームにあらたに行を加える方法を基本から解説します。データフレームにデータを追加するときに、あれ?どうだったけ?ということはありませんか?行を追加する方法はいくつかありますが、今回はその中でもよく使う3つの方法を解説します。
データフレームに行を追加する
まずはサンプルデータを作っておきましょう。
# ライブラリのインポート
import pandas as pd
# サンプルのデータフレーム作成
name = ['らくだ','ねこ','きりん','しまうま','はりねずみ']
zoo = ['上野動物園','上野動物園','宇都宮動物園','ズーラシア','旭山動物園']
age = [38,32,39,45,31]
df = pd.DataFrame({'なまえ':name, 'どうぶつえん':zoo, 'ねんれい':age})
df = df.set_index('なまえ')
df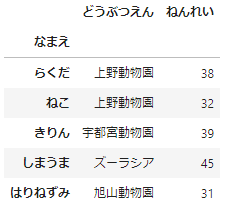
df.loc[] を使って行を追加する
df.loc[] を使って行を追加することができます。データフレームからデータを抽出するときによく使うメソッドなのでわかりやすいですね。気を付ける点は、「存在しない行名」を指定する、df.iloc[]では行の追加はできない、という点です。
やってみましょう。
「存在しない行名」と新しい値を指定するだけで追加することができます。ここでは、「らいおん」を追加することにしましょう。
# 「らいおん」のデータを追加する
df.loc['らいおん',:] = ['ズーラシア',41]
df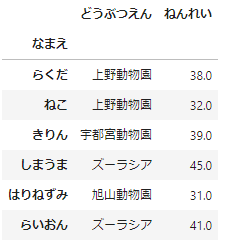
データフレームに存在しない行名「らいおん」を指定したので、新規データの追加ができました。
▶ df.loc[], df.iloc[]の理解があやふやな方はこちらの投稿を参考にしてください。

df.append()を使って行を追加する
次にdf.append()を見ていきましょう。まずは書式の確認です。
「追加するデータ」はSeriesやデータフレームを指定を指定します。さっそく試してみましょう。
まずはSeriesを指定する場合です。元のデータフレームの列名とSeriesのインデックスが対応します。(※一致しない場合は欠損値NaNとなる)また、Seriesのname属性が新たな行名となります。
Seriesにname属性が設定されていないとエラーとなるので注意しましょう。
# 追加するSeriesデータを作成
pengine_sr = pd.Series(['旭山動物園', 29], index=df.columns, name='ぺんぎん')
# df.append()でSeriesのデータを追加
df = df.append(pengine_sr)
df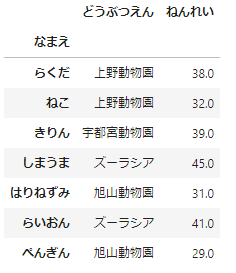
今回は「ぺんぎん」のデータを追加してみました。うまくいってますね。元のデータフレームの列名とSeriesのインデックスが対応しているのがポイントです。しっかり押さえておきましょう。
次にデータフレームを指定する場合を見てみましょう。
# 追加するデータフレームを作成
add_df = pd.DataFrame([['上野動物園',33],['ズーラシア',21]],index=['さる','いぬ'] , columns=['どうぶつえん','ねんれい'] )
add_df

このデータをdf.append()で追加してみましょう。
# df.append()を使ってデータフレームを追加
df = df.append(add_df)
df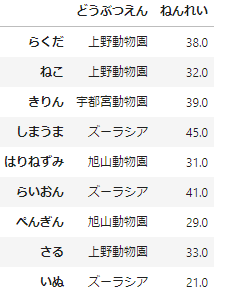
ちゃんと、「さる」と「いぬ」のデータが追加されてますね。df.loc[]での追加の場合と異なり、df.append()では既存の行名であっても追加できてしまうので、注意しましょう。
pd.concat()を使って行を追加する
最後にpd.concat()での行の追加を紹介します。こちらも先に書式を確認しておきましょう。
concatでSeriesを使うこともできますが、Seriesの場合はdf.append()を使った方がわかりやすいです。そのため、concatはデータフレームで使うものと覚えておけばよいでしょう。
※Seriesでの挙動が気になる方はpd.concat([df1, Series])を試してみましょう。期待する結果ではないかと思います。
では、試してみましょう。
# 追加するデータフレームを作成
df2 = pd.DataFrame({'どうぶつえん':'上野動物園','ねんれい':27},index=['ぱんだ'])
# pd.concat()でデータフレームに行を追加
df = pd.concat([df, df2])
df
まとめ
今回はデータフレームに行を追加する方法を基本から解説しました。
df.loc[]を使う方法はわかりやすいですが、既存の行名を指定してしまうとデータを上書きしてしまうので注意が必要です。df.loc[]で行を追加する場合は、「存在しない行名」を指定することに注意します。
2つめのdf.append()を使う方法では、Seriesとデータフレームを扱うことができます。Seriesを追加する場合は、元のデータフレームの列名とSeriesのインデックスが対応となります。Seriesのname属性が新たな行名となります。Seriesにname属性が設定されていない場合は、デフォルトではエラーとなります。ignore_index=Trueとするとname属性が設定されていない場合でも行の追加ができますが、その場合は、行名indexがすべて無視され0始まりの連番となります。
最後にpd.concat()による行の追加ですが、基本的にデータフレームを追加する場合に使う、と考えておくとよいでしょう。
コメント