
- データ分析をはじめたいが、どのように学習を進めればよいかわからない方
- データ分析の基本的な部分の全体像を把握しておきたい方
- データ分析の勉強を始めたが、進め方に迷っている方
はじめに
Pythonでデータ分析を始めたい方を対象に、簡単な入門記事を書いています。今回は、学習用に提供されているデータセットについて解説します。データ分析の学習を進めていると、実際にデータを使って試してみたくなることがあるでしょう。そうしたときにサンプルデータを一から作るのは大変です。ぜひ、学習用に用意されたデータセットを使ってみてください。この記事を読むと、seabornで用意されている学習用データセットを扱うことができるようになります。
学習用データセット
データ分析の学習をしていると、実際に手元のデータで試したくなることがありますね。Pythonで学習を進めている方なら、簡単に学習用のデータセットを入手することができます。機械学習用のライブラリ「scikit-learn」や可視化ライブラリの「seaborn」にはあらかじめデータセットが用意されています。今回はseabornの学習用データセットを利用する手順を確認していきましょう。
seabornの学習用データセット
データセットの一覧をみる
まずは、用意されている学習用データセットにどんなものがあるかを見る方法です。これは、「get_dataset_names()」という関数があらかじめ用意されています。早速みてみましょう。
# ライブラリのインポート
import seaborn as sns
import pandas as pd
# データセットの一覧を取得
print(sns.get_dataset_names())
「get_dataset_names()」の名前の通り、用意されているデータセットの名前が返ってきます。この中から利用したいデータセットを探しましょう。
データセットをloadする
利用したいデータセットを決めたら、実際にデータセットをloadしてみましょう。データセットのloadには、「load_dataset()」という関数が用意されています。scikit-learnライブラリのデータセットはモジュールに組み込まれているのですが、seabornのデータセットはモジュールに埋め込まれているわけではなく、オンラインレポジトリからダウンロードするためインターネットに接続している必要があります。
早速やってみましょう。今回は「car_crashes」のデータをloadしてみましょう。
# データのload
df_car_craches=sns.load_dataset('car_crashes')
df_car_craches.head()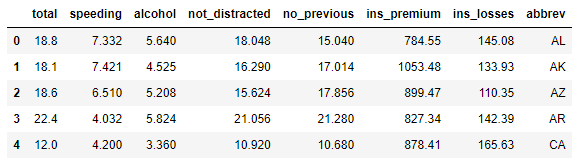
「load_dataset()」の中でデータセット名を指定するだけです。返り値はデータフレームとなります。各カラムが何を意味しているか、いまいちわかりませんが、事故時のスピードや血中のアルコール濃度などが記録されているのでしょうか?
データセットのloadは簡単なので、データセットの一覧をみてもよくわからなければ実際にデータをloadしてみて眺めてみるとよいですね。
まとめ
今回は学習用データセットの使い方を解説しました。scikit-learnやseabornのようにPythonのライブラリには学習用のデータセットが用意されている場合があります。seabornではモジュールに埋め込まれているわけではないのでインターネットに接続されている必要がありますが、簡単に利用することができます。
コメント