
はじめに
今回も時系列データを処理する際によく利用するものを見ていきましょう。pandasのshift( ) メソッドとrolling( )メソッドです。shift( )はデータをズラすことができます。通常、diff( )メソッドがあれば差分をとることができるのですが、shift( )メソッドを使うと、「期間」を指定した処理をすることができます。
サンプルデータの作成
今回は前回と同じデータを使うことにしましょう。あるWebサイトのアクセスデータとします。
# ライブラリのインポート
import pandas as pd
import random
# 日付データの作成
dates=pd.date_range('2020-09-01','2020-09-30')
# アクセスデータの作成
access_list=[random.randint(5000, 20000) for i in range(len(dates))]
# データフレームの作成
df_webdata=pd.DataFrame({'日付':dates,'アクセス数':access_list})
df_webdata.head()
shift( )メソッド
Shift( )はデータをずらすことができます。defaultではデータを1行分ズラします。さっそく見てみましょう。
df_webdata['shift:1']=df_webdata['アクセス数'].shift()
df_webdata.head(10)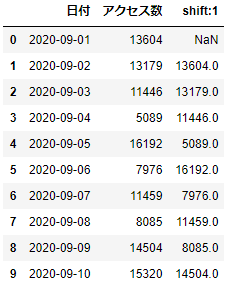
このようにデータをズラすことができるため、差分の計算や変化率を算出しやすくなります。shift( )ではN行分の指定だけでなく、引数freqで期間を指定できるところに特徴があります。引数freqでは、D(日)、H(時間)などの頻度コードを指定することができます。
このとき、たとえば5日分ズラすときには、freq=’5D’という指定の仕方と、periods=5, freq=’D’ のように引数periodsとfreqを組み合わせて指定する方法があります。
まず日付データをインデックスにしておきましょう。
df_webdata=df_webdata.set_index('日付')
df_webdata.head()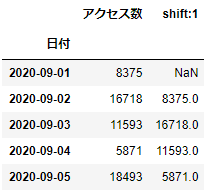
これで日付部分がインデックスになりました。早速、shift( )の引数freqを使ってみましょう。
df_webdata['shift:5']=df_webdata['アクセス数'].shift(freq='5D')
df_webdata.head(15)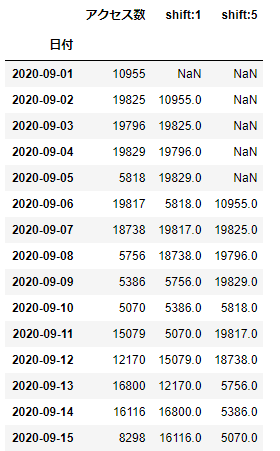
5日分ズラしたデータを作成することができました。ところで、freqではWやMも指定することができますが、注意が必要です。Wは一週間を表すわけではない、Mは一か月を表すわけではない、という点です。
Wは次の日曜日、Mは次の月末にインデックスが変わります。
まとめ
いかがでしたか?時系列データではデータをズラして、そのデータとの差分をとったり、変化率を計算することがあります。通常、diff( )やpct_change( )の処理で十分かと思いますが、shift( )のようにズラす処理を知っておくと、便利なこともあります。是非、身につけておきましょう。
コメント