
はじめに
今回はクロス集計を扱います。クロス集計は目に触れる機会も多く、なじみ深い人も多いのではないでしょうか?情報を整理して捉えやすいので、便利ですよね。EXCELではなじみにある集計方法ですね。今回はPythonでクロス集計する方法をみていきましょう。
クロス集計
クロス集計とは複数項目からなるデータがある時に、異なる属性などに分類して、その頻度数を集計したものを指します。
現場で使える! PANDASデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法
pandasのcrosstab関数により、簡単にクロス集計をすることができます。
サンプルデータ
今回はKaggleのデータを使うことにしましょう。
data=pd.read_csv('C:/data/train.csv')
data.head()
crosstab関数
では、さっそくcrosstab関数を使っていきましょう。crosstab関数のindex引数はクロス集計後のテーブルのインデックスラベルを指定します。columns引数はクロス集計後のカラムラベルを指定します。index, columns引数、ともに配列またはシリーズ、複数の場合はリストで指定できます。
pd.crosstab(index=data['Sex'],columns=data['Embarked'])
複数のインデックスやカラムを指定することも可能です。これも試してみましょう。
pd.crosstab(index=[data['Sex'],data['Cabin']],columns=data['Embarked'])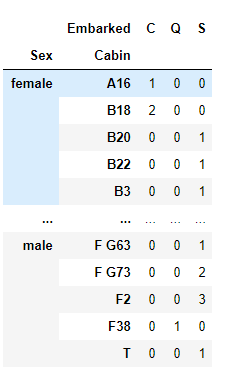
インデックスラベルへ2つのカラムを指定したので、階層型インデックスとして戻されます。また、margins引数(初期値False)により、列と行方向の合算値を算出することもできます。
pd.crosstab(index=data['Sex'],columns=data['Embarked'],margins=True)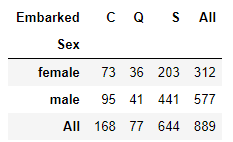
crosstab関数は複数変数間の頻度数を算出しますが、次のようにpivot_table関数のような使い方もできます。
pd.crosstab(
index=data['Sex'],
columns=data['Embarked'],
values=data['Age'],
aggfunc='mean')
まとめ
いかがでしょうか?行方向index、列方向columnsを指定することさえ理解しておけば難しくないですね。データを把握する際に使うことも多いと思います。
コメント