
はじめに
このブログでも、これまで何度もpandas.mergeを使ってきました。いつも決まった操作ばかりだったので不便はなかったのですが、他にもできることあるのでは?とあらためてpandas.mergeをとりあげることにしました。
結合の基本
以前、このブログでも結合の再確認で取り上げているので、今回の投稿では詳しくは扱いません。

結合するときに「key」と「結合の仕方」を指定すれば、とりあえず普段のやりたいことは問題なく処理できます。「key」を指定するときに、2つのデータフレームの「key」の列名が同一であれば、on=’列名’で指定し、異なる場合は、left_on=’左のデータフレームで使うkeyの列名’, right_on=’右のデータフレームで使うkeyの列名’ とするのでした。
「結合の仕方」に関しては、大きく内部結合と外部結合にわけることができ、外部結合は、さらに左外部結合、右外部結合、完全外部結合などを指定することができます。これらは、引数howで指定することができ、inner(内部結合), outer(完全外部結合), left(左外部結合), right(右外部結合) となります。
サンプルデータの作成
結合を確認するためのデータを作っていきましょう。ここでは2つのデータフレームをつくります。まずは必要なライブラリをインポートします。
# 必要なライブラリのインポート
import pandas as pd
import numpy as np
import random
# 日付のリストをつくる
date_list1=random.choices(pd.date_range('2020-09-01','2020-09-30'),k=40)
date_list1=np.array(date_list1)
date_list2=random.choices(pd.date_range('2020-09-01','2020-09-30'),k=40)
date_list2=np.array(date_list2)
# 売上のリストをつくる
sales_list=random.choices(range(100000,350000),k=40)
sales_list=np.array(sales_list)
# 訪問者のリストをつくる
number_visitor=random.choices(range(5,10),k=40)
number_visitor=np.array(number_visitor)
# データフレームを作る
df1=pd.DataFrame({'売上日':date_list1,
'売上金額':sales_list})
df2=pd.DataFrame({'日付':date_list2,
'訪問人数':number_visitor})これで、2020年9月の日別の売上データ(df1)と2020年9月の日別の訪問者のデータ(df2)ができました。各データフレームの中身を確認しておきましょう。
df1.head()
df2.head()
いま、df1は売上日が重複していて、df2は日付が重複しています。そこでそれぞれ、売上日、日付で集計しておきましょう。
df1=df1.groupby('売上日').sum().reset_index()
df2=df2.groupby('日付').sum().reset_index()データフレームの中身を確認しておくと、
df1.head()
df2.head()
簡単な結合の確認
それでは結合してみましょう。結合の基本のところで確認したように、keyと結合方法を指定します。ここではdf1のkeyは売上日、df2のkeyは日付になります。結合方法については内部結合としましょう。
union_df=pd.merge(df1,df2,left_on='売上日',right_on='日付',how='inner')
union_df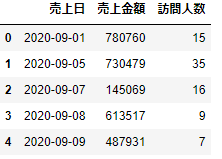
その他のできること
インデックスをキーに結合する
知っていれば当たり前ですし、むしろ結合の時にこっちから習った方もいらっしゃるかもしれませんが、インデックスをkeyにした結合をすることができます。今回のデータでそのままインデックスによる結合をするとおかしなことになるので、df1/df2でそれぞれ売上日/日付をインデックスにして、インデックスによる結合を確認してみましょう。
# df1で売上日をインデックスにする
df1=df1.set_index('売上日')
df1.head()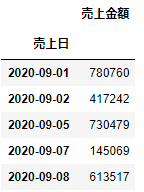
# df2で日付をインデックスにする
_df2=df2.set_index('日付')
_df2.head()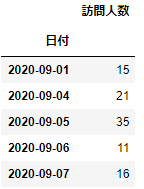
この2つのデータフレーム_df1と_df2をインデックスをkeyにして結合するには、引数left_index、right_indexをTrueにします。
union2=pd.merge(_df1,_df2,left_index=True,right_index=True)
union2.head()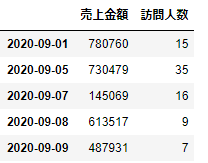
このように共通キーがインデックスのときに、わざわざunstackして列項目にする必要はなく、インデックスのままキーとして指定できます。
元データの情報を表示
外部結合をした場合は、2つのデータフレームのどちらかにしかないレコードも結合後のデータフレームに存在することになります。そのときに、どちらのデータフレーム由来のデータであったかを知りたいことがあります。そんなときに便利なのが引数indicatorとなります。
まず外部結合をしてみると
union3=pd.merge(_df1,_df2,left_index=True,right_index=True,how='outer')
union3.head()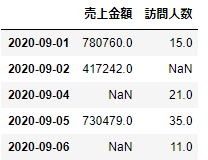
列項目が少ないときには自明ですが、2つ目のレコードはdf1,df2のどちらにあったデータなのか、を簡単に判別できるようにするのがindicatorです。この引数をTrueに指定します。
union3=pd.merge(_df1,_df2,left_index=True,right_index=True,how='outer',indicator=True)
union3.head()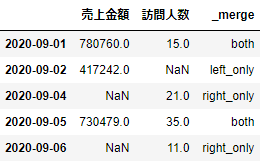
このように「_merge」という列ができて、ここに元のデータフレームの情報が表示されます。bothはdf1/df2どちらにもあったもの、left_onlyはdf1にのみあったもの、right_onlyはdf2にのみあったもの、という意味となります。
この「_merge」という列項目は少しわかりにくいですね。これを簡単に変更することができます。引数indicatorの指定時にTrueの代わりに、設定したい列項目を文字列で指定することで実現できます。やってみましょう。
union3=pd.merge(_df1,_df2,left_index=True,right_index=True,how='outer',indicator='ソース')
union3.head()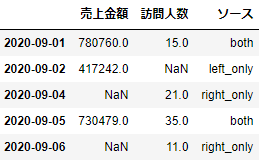
ここでは「ソース」という列項目にしてみました。ちゃんとできてますね!
まとめ
いかがでしたか?まだ他にも引数はありますが、あまり詰め込んでも消化しきれないので、基本的なものをおさえて、あとは必要になった際に調べて知識を加えていくとよいでしょう。
コメント