
はじめに
データの概要を把握する過程やまたは分析する過程においても、グループ化はとても大切な手法となります。それは、グループごとに比較することで、あるグループの特徴的な部分を知ることができるからです。「特徴的な部分」を知ることができれば、何故そのような特徴があるのか?と分析を進めることができます。
データの準備
ここでは、ある小学校の高学年(4,5,6年)/クラス(A,B,C)の身長のデータがあるとします。次のコードでデータを作りました。
# ライブラリのインポート
import numpy as np
import pandas as pd
import random
# データの作成
height_4=np.random.randint(145,155,32)
height_5=np.random.randint(150,160,30)
height_6=np.random.randint(155,165,28)
class_list=['A','B','C']
group_4=pd.DataFrame({'grade':[4]*len(height_4),'class':random.choices(class_list,k=len(height_4)),'height':height_4})
group_5=pd.DataFrame({'grade':[5]*len(height_5),'class':random.choices(class_list,k=len(height_5)),'height':height_5})
group_6=pd.DataFrame({'grade':[6]*len(height_6),'class':random.choices(class_list,k=len(height_6)),'height':height_6})
df=pd.concat([group_4,group_5,group_6])
df.sample(frac=1).reset_index(drop=True)すると、次のようなデータができます。
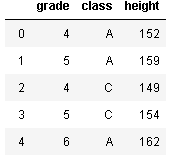
このデータを使って、集計していきましょう。
groupby
まずは学年ごとの身長の平均をみてみます。「学年ごと」なので、学年でgroupbyをおこないます。
df.groupby('grade').mean()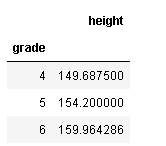
学年が上がるにつれて、身長の平均値もあがっているのがわかります。いま、groupbyで指定した「grade」はindexとして扱われています。indexとして扱いたくなければ次のようにas_indexオプションで指定できます。
df.groupby('grade',as_index=False).mean()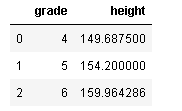
groupbyは、複数の列を指定することもできます。ここでは、学年とクラスでグループ化してみます。
df.groupby(['grade','class'],as_index=False).mean()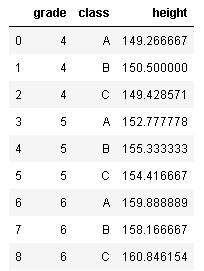
ここまでは、データフレームが持っている情報でのグループ化をおこないましたた。実は、groupbyは外部のデータでもまとめることができます。いま、このデータフレームは90個のレコードがあります。性別の外部データ90個を用意して、次のようにすることができます。
sex=['男','女']
sex_list=random.choices(sex,k=90)
df.groupby(sex_list).mean()['height']
またgroupbyで作成したオブジェクトで、特定の値のものを抽出したいときには、次のようにすることができます。
ここでは、gradeでgroupbyオブジェクトを作成して、5年生のデータのみ抜き出したい、とします。
df_grade.get_group(5)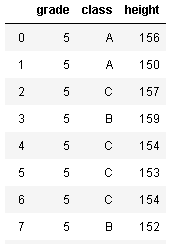
最後に、groupbyオブジェクトを使ったforループを見ておきましょう。
for name, group in df_grade:
print(name)
print(group.head())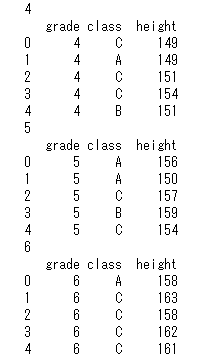
まとめ
いかがでしたでしょうか?groupbyもなかなか奥が深いでしょう。分析するときには、split → apply → combine でデータの概要をつかむ、という方法がありますが、groupbyはまさにこの作業を担うものとなります。しっかりと使いに越したいですね。
コメント